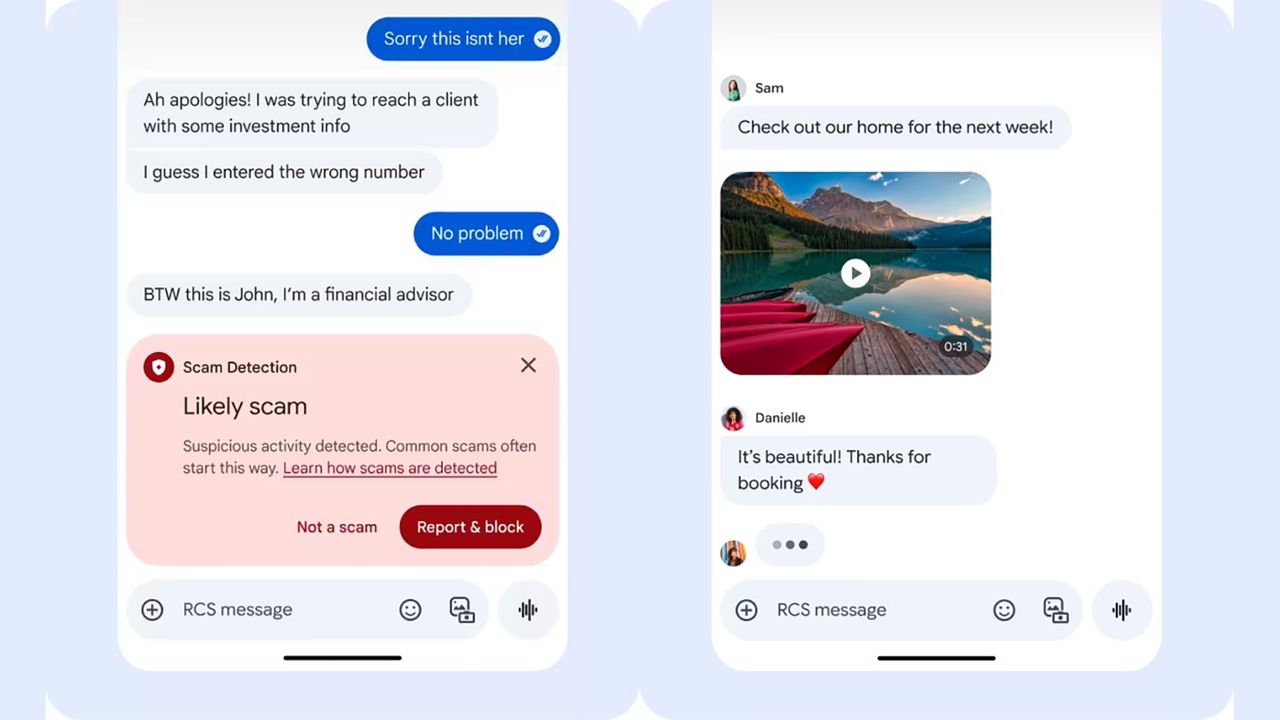
X expands AI translations and adds in-stream photo editing
The app also updated reply settings, allowing paying X users to give second degree connections the ability to comment on posts.
The app also updated reply settings, allowing paying X users to give second degree connections the ability to comment on posts.
The brief comment function is being expanded beyond mutual followers and could potentially become a new way for creators to broadcast information.
The app highlighted the popularity of its public discussions during March Madness, though Threads and X still have more active users during live events.
New demographic data points could be valuable for brand partners, while Google’s latest Nano Banana model will help with image generation.
There may be opportunities for wellness brands that want to engage with people beyond the confines of a doctor’s office, according to a new study from the company.
New insight from the platform highlights the importance of variable signals within Pin recommendations.











Google CEO Sundar Pichai said AI models could expose more software vulnerabilities and agreed it was plausible AI is affecting zero-day exploit markets.
The post Pichai Says AI Could ‘Break Pretty Much All Software’ appeared first on Search Engine Journal.

Google is giving advertisers new visibility into whether its automated recommendations actually drive performance — a long-standing blind spot in the platform.
What’s happening. A new “Results” tab within Recommendations shows the incremental impact of bidding and budget changes after they’ve been applied, allowing marketers to evaluate outcomes instead of relying on assumptions.

How it works. The feature attributes performance changes to specific recommendations, helping advertisers understand what effect adjustments like budget increases or bid strategy shifts had on results.
Why we care. Marketers can now validate whether recommendations improved performance, making it easier to decide which automated suggestions are worth adopting in the future.
Between the lines. Google has a vested interest in encouraging adoption of its recommendations, so providing performance data could build trust — but it also raises questions about how that impact is measured.
The catch. Advertisers may question whether the reported results are fully objective or skewed toward showing positive outcomes, given Google’s incentives.
What to watch. How detailed and transparent the reporting becomes — and whether advertisers see mixed or negative results alongside wins.
Bottom line. Google is moving from “trust us” to “here’s the proof,” but advertisers will be watching closely to see how impartial that proof really is.
First seen. This update was first spotted by Arpan Banerjee who shared seeing the new tab on LinkedIn.

Google is giving advertisers more control over how AI generates ad copy, making it easier to scale campaigns without losing brand consistency.
What’s happening. Google Ads is rolling out a beta feature that allows marketers to copy text guidelines from existing campaigns and apply them to new ones, eliminating the need to rewrite brand rules from scratch.
How it works. Advertisers can replicate approved tone, style and messaging rules across campaigns in one click, ensuring AI-generated ads stay aligned with brand standards while reducing setup time.

Why we care. The feature helps teams launch campaigns faster by reusing what already works, while maintaining consistency across large accounts where multiple campaigns run simultaneously.
Between the lines. This shift reflects a growing demand from marketers to “train” AI systems rather than rely on them blindly, effectively turning brand guidelines into reusable inputs for automation.
Bottom line. AI is speeding up ad creation, but control is becoming the real differentiator — and Google is starting to hand more of it back to advertisers.
First spotted. This update was spotted by Paid Media expert Arpan Banerjee when he shared spotting the alert on LinkedIn.










ZeroTwo lets you access the combined capabilities of Claude, Perplexity, ChatGPT, Manus, and Higgsfield. These top AI platforms each have unique features that give them special abilities beyond their models. Now you can use all of them without paying for several subscriptions. Perplexity's agentic search, Claude's agentic connector, ChatGPT's apps, and Higgsfield's AI tools for creatives are all available on one platform.
The platform also offers deep research, canvas mode, and shared access to threads and projects. Plans include unlimited messages, expanded memory, priority performance, and team features for businesses.
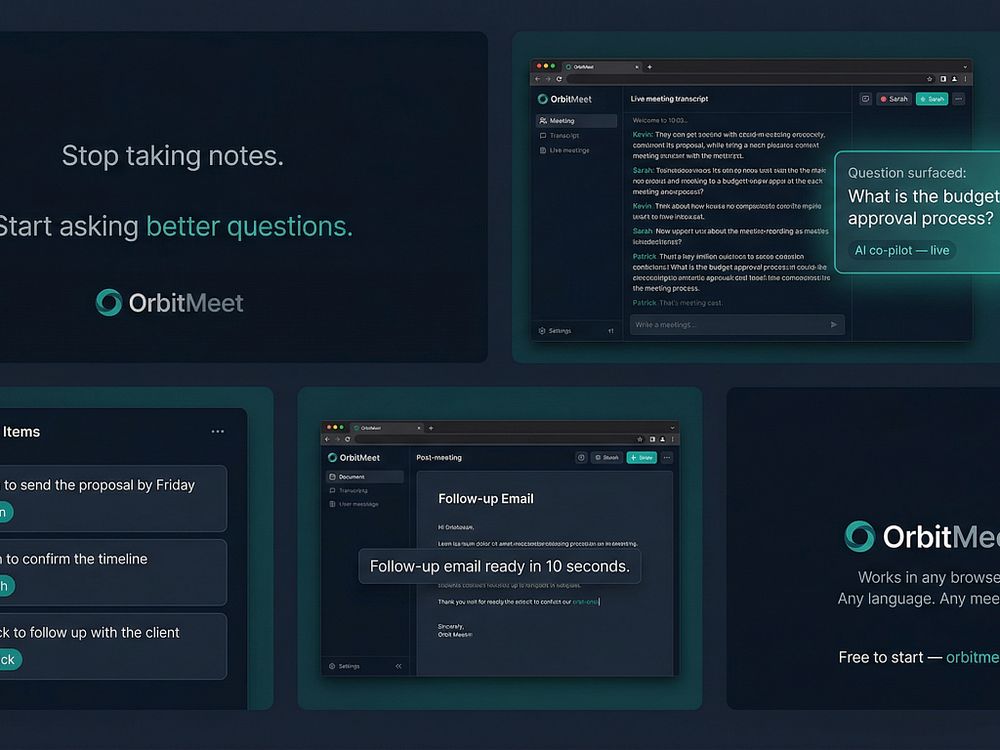
OrbitMeet is a browser-based AI meeting co-pilot that listens to your meetings in real time, surfaces questions you might miss every 75 seconds, and builds your summary as you talk with no plugins or installation.
It detects action items by speaker name, generates follow-up documents such as emails, memos, and action trackers in seconds, and works across Zoom, Teams, Google Meet, or in-person meetings. It's designed for consultants, founders, and distributed teams working in multiple languages. A free plan is available, with Pro at $20.5 CAD/month.



Google says its AI-powered advertising tools are starting to deliver meaningful results, including major revenue gains for some retailers, as it experiments with how ads work in AI-driven search.
The big picture. Fears that AI chatbots like ChatGPT would disrupt Google’s core search business haven’t materialized, and instead the company’s ads business continues to grow, suggesting AI may be expanding how people search rather than replacing it.
By the numbers:
What’s happened. Google is embedding ads into its AI-powered search experiences, including AI Mode powered by Gemini, while introducing new ad formats designed for conversational queries and tools that allow brands to shape how they appear in AI-generated answers, with a new “business agent” feature enabling companies like Poshmark and Reebok to control how their products are represented.
Driving the results. AI-driven campaigns like Performance Max and AI Max match ads to more detailed and conversational search intent, and Google says queries in AI Mode are often two to three times longer than traditional searches, giving the system more context to connect users with relevant products, as seen with Aritzia, which reported an 80% increase in revenue after adopting AI Max.
How it works. The system scans a retailer’s website and creative assets, interprets user intent from conversational queries, and dynamically matches products and messaging in real time. This is increasingly important given that 15% of daily searches are entirely new (according to Google) and cannot be predicted through traditional keyword targeting.
Why we care. Google is shifting from keyword-based ads to intent-driven, AI-matched advertising, meaning campaigns can reach consumers with far more precision at the moment they’re ready to buy. As search becomes more conversational and unpredictable, advertisers who rely on traditional targeting risk falling behind those using AI-driven formats that automatically adapt to new user behavior.
Zoom in. Google is testing new formats such as “direct offers,” which deliver personalized promotions when users show purchase intent, using Gemini to analyze conversational context and behavior, with brands like E.l.f. Beauty, Chewy and L’Oréal participating in early trials.
Commerce push. Google is also advancing its commerce strategy through a Universal Commerce Protocol developed with Shopify, which allows purchases to happen directly within AI conversations.
Yes, but. Google is not alone in experimenting with ads in AI search, and early results across the industry have been mixed, as Amazon has reportedly seen limited traction from ads in its AI shopping assistant, OpenAI continues to explore monetization models, and Perplexity AI has begun phasing out ads after underwhelming performance.
What they’re saying, Google positions itself as a “matchmaker” rather than a retailer, emphasizing that AI helps deliver more relevant and personalized ads while allowing brands to maintain control over their messaging and build user trust by showing the right product at the right moment.
What’s next. Gooogle says it has no current plans to introduce ads directly into Gemini but will continue testing and expanding advertising within AI Mode, including more personalized offers and AI-driven shopping experiences.
Bottom line. AI is not replacing search but reshaping it, and for Google that shift is making advertising more conversational, more targeted and, in some cases, significantly more profitable.
Dig deeper. Google says its AI-powered ads help some brands lift online sales by 80%.

Google Search is evolving beyond links and answers into a system that completes tasks, potentially fundamentally changing how users interact with the web. That’s according to Alphabet CEO Sundar Pichai, speaking on the Cheeky Pint podcast.
Why we care. Google is signaling a move from information retrieval to task execution.
Search becoming agentic. Traditional search behavior is already changing and will continue to, Pichai said.
Pichai also described a future where Google Search acts less like a list of results and more like a system that coordinates actions:
AI Mode is already changing queries. Users are already adapting their behavior in Google’s AI-powered search experiences, Pichai said:
Search vs. Gemini overlap. Despite the rise of Gemini, Pichai said Google isn’t replacing Search with a chatbot. Instead, the two will coexist — and diverge (echoing what Liz Reid said last month):
The interview. The history and future of AI at Google, with Sundar Pichai


Google’s AI Overviews answered a standard factual benchmark correctly 91% of the time in February, up from 85% in October, according to a New York Times analysis with AI startup Oumi.
However, Google handles more than 5 trillion searches per year, so that means tens of millions of answers every hour may be wrong.
Why we care. We’ve watched Google shift from linking to sources to summarizing them for more than two years. This report suggests AI Overviews are improving, but still mix correct answers, weak sourcing, and clear errors in ways that can mislead searchers and reshape which publishers get visibility and clicks.
The details. Oumi tested 4,326 Google searches using SimpleQA, a widely used benchmark for measuring factual accuracy in AI systems, the Times reported. It found AI Overviews were accurate 85% of the time with Gemini 2 and 91% after an upgrade to Gemini 3.
What changed. Accuracy improved between October and February, but grounding worsened. In October, 37% of correct answers were ungrounded; in February, that rose to 56%.
Examples. The Times highlighted several misses:
Google’s response: Google disputed the Times analysis, saying the study used a flawed benchmark and didn’t reflect what people actually search. Google spokesperson Ned Adriance told the Times the study had “serious holes.”
The report. How Accurate Are Google’s A.I. Overviews? (subscription required)





PeaZip 11.0 refines one of the most capable free archivers with faster browsing, smoother drag-and-drop across tabs, and a cleaner, more responsive UI. The update also improves scaling, adds flexible icon rendering, and introduces batch archive testing, alongside the usual fixes and cleanup.


Shadow OS is the first decision-making app built on 64 hexagrams, the same system Carl Jung studied for over two decades and called his most significant method for surfacing what the unconscious already knows. Other decision apps use random spinner wheels, AI chatbots validate whatever you say, and astrology apps offer forecasts open to interpretation. Shadow OS gives you one committed answer: move forward, hold, or pull back.

BeMusic AI is a free AI music generator that turns text prompts into fully produced, royalty-free songs in under 30 seconds. Choose from 50+ genres, adjust mood, tempo, and energy, and download high-quality WAV or MP3 for videos, games, podcasts, and ads. It also offers tools to write lyrics, create instrumentals, convert audio to MIDI, edit MIDI, make AI covers, remove vocals, extend tracks, and analyze songs. Use it to avoid copyright issues and keep full ownership of every track.



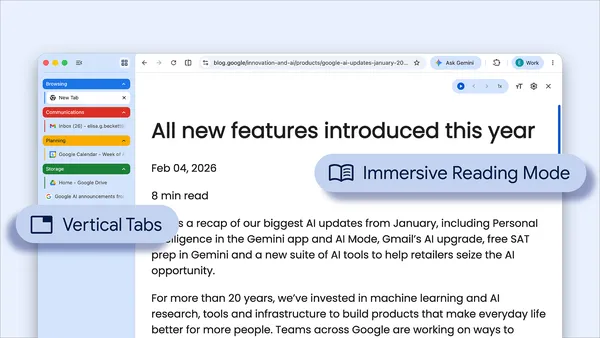 These new features are designed to streamline your browser and help you maximize productivity in Chrome.
These new features are designed to streamline your browser and help you maximize productivity in Chrome. 
Google has begun placing sponsored ad units directly inside the Images tab of mobile search results — a new placement that eligible campaigns can access without any changes to existing keyword targeting.
What’s happening. When a user navigates to the Images tab within Google Search on mobile, they may now see sponsored units appearing within the image grid. Each unit shows a full image creative as the primary visual alongside text, and is clearly labelled “Sponsored” — consistent with how Google labels ads elsewhere in search results.
How it works. Eligible campaigns can serve into the Images tab without any changes to keyword targeting or campaign structure. The placement draws from existing image assets, meaning advertisers running Search or Performance Max campaigns with strong visual creative are best positioned to benefit. No separate image-only campaign setup is required.

Why we care. This is a meaningful expansion of Google’s paid search real estate. For product-led and catalog-heavy advertisers, the Images tab is where purchase-intent discovery often starts — and now ads can appear right in that moment. If your campaigns already use strong image assets, you may be picking up incremental impressions without lifting a finger.
The big picture. Early indications suggest this placement behaves more like a visual discovery surface than classic paid search. Expect high impression volume but lower click-through rates — more in line with display or Shopping than traditional text ads. That said, the assist value in multi-touch conversion paths could be significant, particularly for retail and direct-to-consumer brands. Treat it as upper-funnel reach, not a last-click channel.
What to watch. Google has not made a formal announcement, and there is no dedicated reporting breakdown for Images tab placements yet. Monitor your impression share and segment data closely to understand whether this placement is contributing — and whether it’s eating into organic image visibility for competitors.
First seen. The placement was spotted by Google Ads Expert – Matteo Braghetta, who shared seeing this update on LinkedIn. No official documentation has been published by Google at the time of writing.

Over 30% of outbound clicks go to just 10 domains, with Google alone taking more than 20%, according to a new Semrush study published today.
ChatGPT also relies less on the live web, triggering search on 34.5% of queries, down from 46% in late 2024.
The big picture. ChatGPT’s growth has plateaued, and its role in how users navigate the web is evolving unevenly.
The details. Most ChatGPT referral traffic still goes to a small set of sites, even as more sites receive some traffic.
Why we care. Visibility in ChatGPT doesn’t translate evenly into traffic, and you’ll likely see marginal referral impact. The decline in search-triggered queries also limits your chances to earn citations and traffic.
When ChatGPT searches. It defaults to pre-trained knowledge and uses web search in specific cases, including:
Behavior shift. Most ChatGPT prompts still don’t resemble traditional search queries.
About the data. Semrush analyzed more than 1 billion lines of U.S. clickstream data from October 2024 to February 2026 across a 200 million-user panel, tracking prompts, referral destinations, and search usage.
The study. ChatGPT traffic analysis: Insights from 17 months of clickstream data























 Google doesn’t train Gemini using personal emails. Here’s how Google keeps private data secure in Gmail amid new AI model upgrades.
Google doesn’t train Gemini using personal emails. Here’s how Google keeps private data secure in Gmail amid new AI model upgrades.  Android XR adds spatial conversion for 2D apps, the ability to pin apps to your walls and more ways to watch, create, and explore.
Android XR adds spatial conversion for 2D apps, the ability to pin apps to your walls and more ways to watch, create, and explore.  We’re making it easier for people to share photos and videos, and keep track of their progress.
We’re making it easier for people to share photos and videos, and keep track of their progress. 
Google is rolling out new Google Maps features that make it easier to contribute photos, reviews, and local insights, while adding Gemini-powered caption suggestions.
Local Guides redesign. Contributor profiles are getting more visibility. Total points now appear more prominently, Local Guide levels are easier to spot, and badge designs have been refreshed.
AI caption drafts. Google is also introducing AI-generated caption drafts. Gemini analyzes selected images and suggests text you can edit or discard.
Media sharing. Google Maps now shows recent photos and videos directly in the Contribute tab, making uploads faster.
Why we care. Google is making it easier to create and scale fresh local content, which can directly affect rankings and visibility. At the same time, stronger contributor signals may influence which reviews users trust and which businesses win clicks.

Google once attributed two of Barry Schwartz’s Search Engine Land articles to me — a misclassification at the annotation layer that briefly rewrote authorship in Google’s systems.
For a few days, when you searched for certain Search Engine Land articles Schwartz had written, Google listed me as the author. The articles appeared in my entity’s publication list and were connected to my Knowledge Panel.
What happened illustrates something the SEO industry has almost entirely overlooked: that annotation — not the content itself — is the key to what users see and thus your success.
Googlebot crawled those pages, found my name prominently displayed below the article (my author bio appeared as the first recognized entity name beneath the content), and the algorithm at the annotation gate added the “Post-It” that classified me as the author with high confidence.
This is the most important point to bear in mind: the bot can misclassify and annotate, and that defines everything the algorithms do downstream (in recruitment, grounding, display, and won). In this case, the issue was authorship, which isn’t going to kill my business or Schwartz’s.
But if that were a product, a price, an attribute, or anything else that matters to the intent of a user search query where your brand should be one of the obvious candidates, when any aspect of content is inaccurately annotated, you’ve lost the “ranking game” before you even started competing.
Annotation is the single most important gate in taking your brand from discover to won, whatever query, intent, or engine you’re optimizing for.
Indexing (Gate 4) breaks your content into semantic chunks, converts it, and stores it in a proprietary format. Annotation (Gate 5) then labels those chunks with a confidence-driven “Post-It” classification system.
It’s a pragmatic labeler and attaches classifications to each chunk, describing:
Importantly, it’s mostly unopinionated when labeling facts, context, and trustworthiness. Microsoft’s Fabrice Canel confirmed the principle that the bot tags without judging, and that filtering happens at query time.
What does that mean? The bot annotates neutrally at crawl time, classifying your content without knowing what query will eventually trigger retrieval.
Annotation carries no intent at all. It’s the insight that has completely changed my approach to “crawl and index.”
That clearly shows you that indexing isn’t the ultimate goal. Getting your page indexed is table stakes. Full, correct, and confident annotation is where the action happens: an indexed page that is poorly annotated is invisible to each of the algorithmic trinity.
The annotation system analyzes each chunk using one or more language models, cross-referenced against the web index, the knowledge graph, and the models’ own parametric knowledge. But it analyzes each chunk in the context of the page wrapper.
The page-level topic, entity associations, and intent provide the frame for classifying each chunk. If the page-level understanding is confused (unclear topic, ambiguous entity, mixed intent), every chunk annotation inherits that confusion. Even more importantly, it assigns confidence to every piece of information it adds to the “Post-Its.”
The choices happen downstream: each of the algorithmic trinity (LLMs, search engines, and knowledge graphs) uses the annotation to decide whether to absorb your content at recruitment (Gate 6). Each has different criteria, so you need to assess your own content for its “annotatability” in the context of all three.
And a small but telling detail: Back in 2020, Martin Splitt suggested that Google compares your meta description to its own LLM-generated summary of the page. When they match, the system’s confidence in its page-level understanding increases, and that confidence cascades into better annotation scores for every chunk — one of thousands of tiny signals that accumulate.
Annotation is the key midpoint of the 10-gate pipeline, where the scoreboard turns on. Everything before it is infrastructure: “Can the system access and store your content?” Everything after it is competition:

When you consider what happens at the annotation gate and its depth, links and keywords become the wrong lens entirely. They describe how you tried to influence a ranking system, whereas annotation is the mechanism behind how the algorithmic trinity chooses the content that builds its understanding of what you are.
The frame has to shift. You’re educating algorithms. They behave like children, learning from what you consistently, clearly, and coherently put in front of them. With consistent, corroborated information, they build an accurate understanding.
Given inconsistent or ambiguous signals, they learn incorrectly and then confidently repeat those errors over time. Building confidence in the machine’s understanding of you is the most important variable in this work, whether you call it SEO or AAO.

In 2026, every AI assistive engine and agent is that same child, operating at a greater scale and with higher stakes than Google ever had. Educating the algorithms isn’t a metaphor. It’s the operational model for everything that follows.
For a more academic perspective, see: “Annotation Cascading: Hierarchical Model Routing, Topical Authority, and Inter-Page Context Propagation in Large-Scale Web Content Classification.”
When mapping the annotation dimensions, I identified 24, organized across five functional categories. After presenting this to Canel, his response was: “Oh, there is definitely more.”
Of course there are. This taxonomy is built through observation first, then naming what consistently appears. The [know/guess] distinctions follow the same logic: test hypotheses, eliminate what doesn’t hold up, and keep what remains.
The five functional categories form the foundation of the model. They are simple by design — once you understand the categories, the dimensions follow naturally. There are likely additional dimensions beyond those mapped here.
What follows is the taxonomy: the categories are directionally sound (as confirmed by Canel), while the specific dimension assignments reflect observed behavior and remain incomplete.

Across all five levels, a confidence score is attached to every individual annotation. Not just what the system thinks your content means, but how certain it is.
Clarity drives confidence. Ambiguity kills it.
Canel also confirmed additional dimensions I had not initially mapped: audience suitability, ingestion fidelity, and freshness delta. These sit across the existing categories rather than forming a sixth level.
In 2022, Splitt named three annotation behaviors in a Duda webinar that map directly onto the five-level model. The centerpiece annotation is Level 2 in direct operation:
Annotation runs before recruitment, which means a chunk classified as non-centerpiece carries that verdict into every gate that follows. Boilerplate detection is Level 3: content that appears consistently across pages — headers, footers, navigation, and repeated blocks — enters a different competition pool based on its structural role alone.
Off-topic routing closes the picture. A page classified around a primary topic annotates every chunk relative to that centerpiece, and content peripheral to the primary topic starts its own competition pool at a disadvantage before Recruitment begins.
Splitt’s example: a page with 10,000 words on dog food and a thousand on bikes is “probably not good content for bikes.” The system isn’t ignoring the bike content. It’s annotating it as peripheral, and that annotation is the routing decision.
In Sydney in 2019, I was at a conference with Gary Illyes and Brent Payne. Illyes explained that Google’s quality assessment across annotation dimensions was multiplicative, not additive.
Illyes asked us not to film, so I grabbed a beer mat and noted a simple calculation: if you score 0.9 across each of 10 dimensions, 0.9 to the power of 10 is 0.35. You survive at 35% of your original signal. If you score 0.8 across 10 dimensions, you survive at 11%. If one dimension scores close to zero, the multiplication produces a result close to zero, regardless of how well you score on every other dimension.
Payne’s phrasing of the practical implication was better than mine: “Better to be a straight C student than three As and an F.”
The beer mat went into my bag. The principle became central to everything I’ve built since.

The multiplicative destruction effect has a direct consequence for annotation strategy: the C-student principle is your guide.
At the annotation stage, misclassification, low confidence, or near-zero on one dimension will kill your content and take it out of the race.
Nathan Chalmers, who works at Bing on quality, told me something that puts this in a different light entirely. Bing’s internal quality algorithm, the one making these multiplicative assessments across annotation dimensions, is literally called Darwin.
Natural selection is the explicit model: content with near-zero on any fitness dimension is selected against. The annotations are the fitness test. The multiplicative destruction effect is the selection mechanism.
The system doesn’t use one giant language model to classify all content. It routes content to specialized small language models (SLMs): domain-specific models that are cheaper, faster, and paradoxically more accurate than general LLMs for niche content.
A medical SLM classifies medical content better than GPT-4 would, because it has been trained specifically on medical literature and knows the entities, the relationships, the standard claims, and the red flags in that domain.
What follows is my model of how the routing works, reconstructed from observable behavior and confirmed principles. The existence of specialist models is confirmed. The specific cascade mechanism is my reconstruction.
The routing follows what I call the annotation cascade. The choice of SLM cascades like this:
Each level narrows the SLM selection, and each level either confirms or overrides the routing from above. This maps directly to the wrapper hierarchy from the fourth piece: the site wrapper, category wrapper, and page wrapper each provide context that influences which specialist model the system selects.

The system deploys three types of SLM simultaneously for each topic. This is my model, derived from the behavior I have observed: annotation errors cluster into patterns that suggest three distinct classification axes.
When all three return high confidence on the same entity for the same content, annotation cost is minimal, and the confidence score is very high. When they disagree (i.e., the subject SLM says “marketing,” but the entity SLM can’t resolve the entity, and the concept SLM flags the claims as novel), confidence drops, and the system falls back to a more general, less accurate model.
The key insight? LLM annotation is the failure mode. The system wants to use a specialist. It defaults to a generalist only when it can’t route to a specialist. Generalist annotation produces lower confidence across all dimensions.
Content that’s category-clear within its first 100 words, uses standard industry terminology, follows structural conventions for its content type, and references well-known entities in its domain triggers SLM routing.
Content that’s topically ambiguous or terminologically creative gets the generalist. Lower confidence propagates through every downstream gate.
Now, this may not be the exact way the SLMs are applied as a triad (and it might not even be a trio). However, two things strike me:
Here is something I’ve observed over years of tracking annotation behavior. It aligns with a principle Canel confirmed explicitly for URL status changes (404s and 301 redirects): the system’s initial classification tends to stick.
When the bot first crawls a page, it selects an SLM, runs the annotation, assigns confidence scores, and saves the classification. The next time it crawls the same page, it logically starts with the previously assigned model and annotations. I call this first-impression persistence.
The initial annotation is the baseline against which all subsequent signals are measured. The system doesn’t re-evaluate from scratch. It checks whether the new crawl is consistent with the existing classification, and if it is, the classification is reinforced.
Canel confirmed a related mechanism: when a URL returns a 404 or is redirected with a 301, the system allows a grace period (very roughly a week for a page, and between one and three months for content, in my observation) during which it assumes the change might revert. After the grace period, the new state becomes persistent. I believe the same principle applies to content classification: a window of fluidity after first publication, then crystallization.
I have direct evidence for the correction side from the evolution of my own terminologies. When I first described the algorithmic trinity, I used the phrase “knowledge graphs, large language models, and web index.” Google, ChatGPT, and Perplexity all picked up on the new term and defined it correctly.
A month later, I changed the last one to “search engine” because it occurred to me that the web index is what all three systems feed off, not just the search system itself. At the point of correction, I had published roughly 10 articles using the original terminology.
I went back and invested the time to change every single one, updating every reference, leaving zero traces. A month later, AI assistive engines were consistently using “search engine” in place of “web index.”
The lesson is that change is possible, but you need to be thorough: any residual contradictory signal (one old article, one unchanged social post, and one cached version) maintains inertia proportionally. Thoroughness is the unlock, rather than time.

A rebrand, career pivot, or repositioning is the practical example. You can change the AI model’s understanding and representation of your corporate or personal brand, but it requires thoroughly and consistently pivoting your digital footprint to the new reality.
In my experience, “on a sixpence” within a week. I’ve done this with my podcast several times. Facebook achieved the ultimate rebrand from an algorithmic perspective when it changed its name to Meta.
Get your annotation right before you publish. The first crawl sets the baseline. A page published prematurely (with an unclear topic or ambiguous entity signals) crystallizes into a low-confidence annotation, and changing it later requires significantly more effort than getting it right the first time.
The system doesn’t annotate in a vacuum. When the bot classifies your content at Gate 5, it cross-references against at least three sources simultaneously. This is my model of the mechanism. The observable effect — that annotation confidence correlates with entity presence across multiple systems — is confirmed from our tracking data.
The bot carries prioritized access to the web index during crawling, checking your content against what it already knows:
Against the knowledge graph, it checks annotated entities during classification — an entity already in the graph with high confidence means annotation inherits that confidence, while absence starts from a much lower baseline.
The SLM’s own parametric knowledge provides the third cross-reference: each SLM compares encountered claims against its training data, granting higher confidence to claims that align, flagging contradictions, and giving lower confidence to novel claims until corroboration accumulates.
This means annotation quality isn’t just about how well your content is written. It’s about how well your entity is already represented across all three of the algorithmic trinity. An entity with strong knowledge graph presence, authoritative web index links, and consistent SLM-domain representation gets higher annotation confidence on new content automatically.
The flywheel: better presence leads to better annotation, which leads to better recruitment, which strengthens presence, and which improves future annotation.
Once again, better to have an average presence in all three than to have a dominant presence in two and no presence in one.

And this is why knowledge graph optimization (what I’ve been advocating for over a decade) isn’t separate from content optimization. They are the same pipeline. Your knowledge graph presence directly improves how accurately, verbosely, and confidently the system annotates every new piece of content you publish.
If you’re thinking “Knowledge graph? That’s just Google,” think again.
In November 2025, Andrea Volpini intercepted ChatGPT’s internal data streams and found an operational entity layer running beneath every conversation: structured entity resolution connected to what amounts to a product graph mirroring Google Shopping feeds.
OpenAI is building its own knowledge graph inside the LLM. My bet is that they will externalize it for several reasons: a knowledge graph in an LLM doesn’t scale, an LLM will self-confirm, so the value is limited, a standalone knowledge graph can be easily updated in real time without retraining the model, and it’s only useful at scale when it stays current.
The algorithmic trinity isn’t a Google phenomenon. It’s the architectural pattern every AI assistive engine and agent converges on, because you can’t generate reliable recommendations without a concept graph, structured entity data, and up-to-date search results to ground them.
Google and Bing own their crawling infrastructure, indexes, and knowledge graphs. They can afford grace periods, schedule rechecks, and maintain temporal state for URLs and entities over months.
OpenAI, Perplexity, and every engine that rents index access from Google or Bing operate on a fundamentally different model. They have two speeds:
The Boolean gate inherits Google’s and Bing’s annotations. Whether your content appears at all depends on whether it was recruited from the index those engines draw from, and that recruitment depends on annotation and selection decisions made by the algorithmic trinity. But what these engines show when they cite you is fetched in real time.
For Google and Bing, you’re optimizing for annotation quality with the benefit of grace periods and gradual reclassification. For engines that don’t own their index, the Boolean presence is inherited from the rented index and is slow to change, but the surface-level display changes every time they re-fetch.
That means what you are seeing in the results is not a direct measure of your annotation quality. It’s a snapshot of your page at the moment of fetch, and those two things may have nothing to do with each other.
The SEO industry has spent two decades optimizing for search and assistive results — what happens after the system has already decided what your content means. We should be optimizing for annotation.
If the annotation is wrong, everything downstream suffers. When the annotation is accurate, verbose, and confident, your content has a significant advantage in recruitment, grounding, display, and, ultimately, won.
Make your topic category obvious within the first 100 words. Use standard industry terminology. Follow structural conventions. Reference well-known entities. The goal: specialist model, not generalist.
Clear signals for subject (what is this about?), entity (who is the authority?), and concept (what established ideas does this connect to?). Ambiguity on any axis reduces confidence.
First-impression persistence means the initial annotation is the hardest to change. Publish only when topic, entity signals, and claims are unambiguous.
Knowledge graph presence, web index centrality, LLM parameter strengthening, and correct SLM-domain representation all feed annotation confidence for new content. Invest in entity foundation, and every future piece benefits from inherited credibility.
Change every reference. Leave zero contradictory signals. Noise maintains inertia proportionally.
A page can be indexed and still misannotated. If the AI response is wrong about you, the problem is almost certainly at Gate 5, not Gate 8.

Annotation is the gate where most brands silently lose. The SEO industry doesn’t yet have a vocabulary for it. That needs to change, because the gap between brands that get annotation right and brands that don’t is the gap between consistent AI visibility and permanent algorithmic obscurity.
You’ve done everything within your power to create the best possible content that maps to intent of your ideal customer profile, you have methodically optimized your digital footprint, your data feeds every entry mode simultaneously: pull, push discovery, push data, MCP, and ambient, so they are all drawing from the same clean, consistent source
So, content about your brand has passed through the DSCRI infrastructure phase, survived the rendering and conversion fidelity boundaries, and arrived in the index (Gate 4) intact. Phew!
Now it gets classified. Annotation is the last moment in the pipeline where you have the field to yourself. Every decision in DSCRI was absolute: you vs. the machine, with no competitor in the frame.
Annotation is still absolute. The system classifies your content based on your signals alone, independently of what any competitor has done. Nobody else’s data changes how your entity is annotated.
But this is the last time you aren’t competing. From recruitment onward, everything is relative. The field opens, every brand that passed annotation enters the same competitive pool, and the advantage you carried through the absolute phase becomes your starting position in the competitive race you have to win.
That means:
Warning: First-impression persistence (remember, the first time you are annotated is the baseline) means you don’t get a clean retry. Changing the baseline requires thoroughness, time, and more effort than getting it right on the first crawl.
Annotation isn’t the gate that most brands focus on. It’s the gate where most brands silently lose.
This is the eighth piece in my AI authority series.

SOVOL is about to enter its multi-material era SOVOL has started teasing “something new”, a new 3D printer that promises to be both “multi-material” and “multi-colour”. Until now, SOVOL has specialised in single-colour/material 3D printing solutions, promising “open-source freedom” and a wealth of customisation options. Based on their teaser image, SOVOL’s new 3D printer appears […]
The post SOVOL teases its first multi-filament 3D printer appeared first on OC3D.







Java 26 is here with fresh language features, faster performance, stronger security, and a wave of library and tooling upgrades. Early developer reaction has been upbeat, with many praising Java's steady pace of meaningful improvements.



PanelShot generates realistic AI personas, shows them your website, and delivers structured feedback in minutes. Pick audience segments or create your own, select a research rubric, and let AI evaluate screenshots, copy, and accessibility to surface insights. Review an executive summary and per-page analysis, replay the same personas on new versions, track sentiment trends over time, and chat with any persona for deeper understanding, all for cents per persona.

REWRITE is a 30-day interactive story and voice-first coaching platform that measures personal transformation through your voice. You follow the narrative, talk with an AI coach by text or voice, and see objective signals like stress, confidence, engagement, cognitive load, and authenticity. After the story, daily prompts and monthly voice reports track your progress, giving data you can act on. Coaches get a dashboard with client trends, attention flags, and AI-generated prep notes.












Many of today’s PPC tools were designed to be easily accessible to ecommerce. That doesn’t mean lead gen can’t take advantage of them, but it does mean more intentional application is required.
Lead gen with AI still requires a creative approach, and many conventional ecommerce tools still apply — but not always in the same way.
Here are the priorities that matter most for succeeding with lead gen using AI.
Disclosure: I’m a Microsoft employee. While this guidance is platform-agnostic, I’ll reference examples that lean into Microsoft Advertising tooling. The principles apply broadly across platforms.
This is the single most important thing you can do as AI becomes more embedded in media buying.
Between evolving attribution models, privacy changes, different platform connections, and shifts in how consumers engage with brands, it’s reasonable to ask whether your data is still telling an accurate story.
Start by auditing your CRM or lead management system. Make sure the data you pass back to advertising platforms is clean, consistent, and intentional.
In most cases, data issues stem from human choices rather than technical failures. Still, there are a few technical checks that matter:
If AI systems are learning from your data, you want to be confident that the feedback loop reflects reality.
Dig deeper: How to make automation work for lead gen PPC
Lead gen campaigns often have multiple conversion paths, which can be helpful for users. But from an AI perspective, ambiguity is a risk.
Your landing pages should make it clear:
Redundant or unclear conversion paths can confuse both users and systems. If AI crawlers detect that anticipated outcomes are inconsistent, they may begin to question the accuracy of what your site claims to do. That can limit eligibility for certain placements.
Language clarity matters just as much. Avoid jargon, eccentric terminology, or internally focused phrasing when describing your services. Clear, plain language makes it easier for AI systems to understand who you are, what you offer, and how to match creative to the right audience.
A practical test: Put your website content into a Performance Max campaign builder and review how the system attempts to position your business. If you agree with the messaging, imagery, and framing, your site is likely easy to understand. If not, that feedback is valuable.

You can also paste your site content into AI assistants and ask them to describe your business and services. If the response aligns with reality, you’re in a good place. If it doesn’t, that’s a signal to refine your content.
Behavioral analytics tools, like Clarity, can help you understand exactly how humans are engaging with your site and how often AI tools are crawling your site.
Dig deeper: AI tools for PPC, AI search, and social campaigns: What’s worth using now
Lead gen has always struggled with long conversion cycles. That challenge doesn’t go away, and in some ways, it becomes more pronounced.
AI-driven systems increasingly weigh sentiment, visibility, and contextual signals, not just last-click performance. If all of your budget and reporting focuses on immediate traffic, you may miss meaningful impact higher in the funnel.
That means:
In many lead gen models, citations, qualified leads, and eventual revenue tell a more accurate story than clicks alone.
Dig deeper: Lead gen PPC: How to optimize for conversions and drive results
You may not think you have a “feed” in your lead gen setup, but that absence can put you at a disadvantage.
Feeds help AI systems understand your business structure, services, and site architecture. Even if you don’t have hundreds of pages, a simple, well-maintained feed in an Excel document can provide valuable context when uploaded to ad platforms.

Feed hygiene matters. Use clear, specific columns. Follow platform standards for text, images, and categorization. Make sure all relevant categories are represented.
On the local side, claim and maintain all map profiles. Ensure information is accurate and consistent. If you use call tracking in map placements, review your labeling carefully. AI systems may pull data from map listings or your website, and mismatches can create attribution confusion, particularly for phone leads.
Account for potential AI-driven inflation in reporting, whether you’re looking at map pack data, direct reporting, or site-level performance. Any changes you make should also be reflected correctly in your conversion goals.
Creative assets may be mixed, matched, or shortened using AI. In some cases, you may only get one headline to explain who you are and why someone should contact you.
If your value proposition requires three headlines, or a headline plus a description, to make sense, that’s a risk.
Review your existing creative and identify assets that stand on their own. You should have at least some options where a single headline clearly communicates:
If that clarity isn’t there, AI-driven placements can quickly become confusing.
Dig deeper: Why creative, not bidding, is limiting PPC performance
Lead gen today doesn’t need to be complicated.
Most of the actions that matter today are things strong advertisers already do: clean data, clear messaging, intentional budgeting, and disciplined execution. What changes is how attribution may shift, and how much weight systems place on different signals.
The fundamentals still win. The difference is that AI makes weaknesses more visible and strengths more scalable.
If you focus on clarity, accuracy, and alignment across your funnel, you give both people and systems the best possible chance to understand your business — and that’s where sustainable performance comes from.


























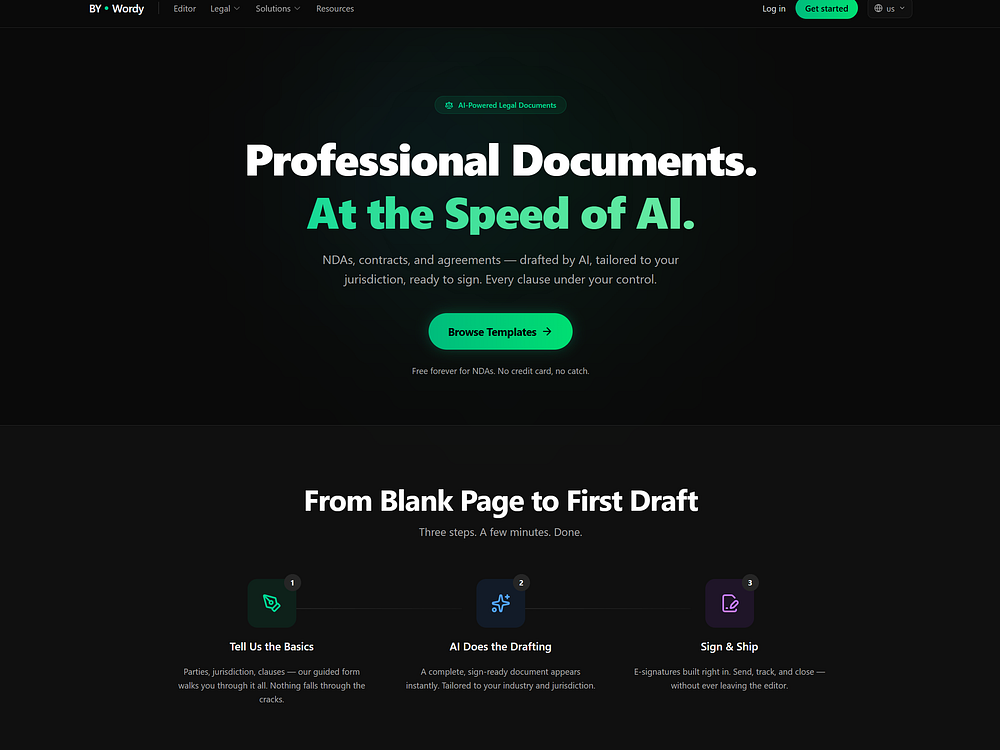
ByWordy is an AI writing workspace for creating contracts, articles, and other documents in your own voice. The platform offers jurisdiction-aware legal documents generated from templates, with e-sign capabilities. You can draft, rewrite, and refine with an AI editor. Legal templates are free to use, and credits are offered upon signing in.
CloverNut centralizes operations for music labels, publishers, workshops, and other creative businesses. Manage artists, products, and releases; build public homepages; and support eight languages with real-time API sync. Handle streaming links for Spotify and Apple Music, create press kits, and control team access with roles. Flexible plans scale from solo creators to enterprises.
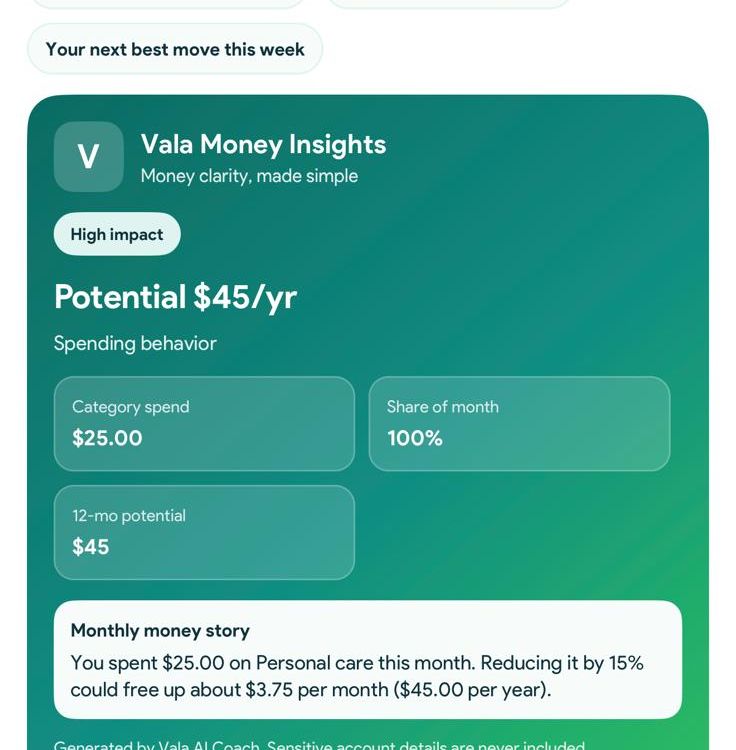
Vala is an AI financial intelligence app that turns transactions into clear insights and practical actions. It connects bank accounts, categorizes expenses, tracks subscriptions, and helps manage shared spending for a simple, complete view of your finances.
Vala also offers goal tracking, budget savings tools, and real-time alerts for bills or unusual spending. With visual insight cards and guided suggestions, it helps individuals, couples, and families understand patterns and make better decisions without manual tracking or complex budgeting.








For most people, “Mad Men” means the TV show. But the phrase points to something more specific: Madison Avenue in the 1950s and ‘60s, when agencies grew brands through persuasion, positioning, and earned trust in a world of scarce media channels and powerful gatekeepers. If you wanted attention, you bought your way in, then made your product the obvious choice.
When the internet arrived and Google made the chaos navigable, an entire industry was built on getting brands found. Search and SEO became one of the most commercially valuable disciplines in marketing.
That model isn’t disappearing. But something new is taking shape on top of it — and most of the industry is still using the wrong language to describe what’s happening.
AI is exposing everything SEO has neglected. Brands that win recommendations from AI systems won’t do so by publishing more content. They’ll win through positioning, persuasion, and corroborated proof.
In other words, they’ll win the way Madison Avenue always did.
One of the strangest things about the current industry conversation is how many people talk as if the job of SEO is to create content. It isn’t. Not for most businesses.
If you’re a publisher, content is the product. Traffic is the commercial engine. But for most brands, content never did what people thought.
Early on, people wrote content for customers, and it worked. Then it changed. Content became a keyword vehicle. “Get people to our site” replaced good marketing comms.
Traffic became a proxy for exposure. It worked because search rewarded retrieval: type a query, get a page, get a click. All you needed to sell that model was the belief that any traffic was good traffic. That traffic somehow led to revenue that your agency could keep delivering.
That model is now under serious pressure.
Google and ChatGPT are increasingly taking the click. Every serious large language model is trying to satisfy informational intent before the user reaches the source. They aren’t trying to be better search engines. They’re trying to make search engines unnecessary — and that’s the entire point.
There’s too much information on the web. People don’t want to open 10 tabs and read five near-identical blog posts to find a basic answer. They want the answer. The AI systems exist precisely to give it to them.
So if informational retrieval gets absorbed into the interface, what remains? Marketing. That’s the part many SEOs are still not fully grappling with.
Dig deeper: The three AI research modes redefining search – and why brand wins
The cleanest way to understand this shift is through the “4 Ps” of marketing: product, price, place, and promotion.
Traditional SEO has been, almost entirely, a place discipline. It’s been about getting your products, services, or information onto the digital shelf when people go looking.
Keyword rankings are shelf position. Paid search is just a more expensive version of the same principle. In commercial search, you pay for premium placement in a digital aisle.
That still matters enormously.
Buyer-intent search remains valuable. Google hasn’t solved its commercial transition to a fully AI-led interface, and won’t overnight. Search is too important to Google’s revenue to disappear fast. But another layer is emerging above it, and this is the layer that most agencies aren’t yet equipped to compete on.
As AI systems become the first interaction point for more users, the game shifts from being present to being preferred.
Users don’t just search. They ask. They describe a problem. They want the best CRM for a mid-market SaaS company, the best estate agent in their area, the best sandwich shop near the office. And the system responds with recommendations.
If classic SEO was about rankings, the next phase is about recommendations. If classic SEO was about digital placement, the next phase is about shaping preference. And recommendation, in practice, is advertising.
Not a display banner. Not a 30-second TV spot. But advertising in the oldest and most commercially powerful sense: influencing the choice someone makes before they’ve even consciously made it.
An AI-generated recommendation is an invisible ad unit. It doesn’t bill by impression.
When an LLM recommends a brand, it can’t know with certainty what will work best. So it infers. It weighs signals: past success, prominence, reviews, case studies, corroborating sources, and repeated associations between a brand and a specific type of problem.
Humans do something almost identical.
Where performance is clearly bounded, we can identify a winner. We know who won the Oscar. We know which film topped the box office.
But when performance isn’t obvious in advance, we rely on proxies. We ask friends, read reviews, and scan for authority. We use familiarity, logic, and social proof to estimate what is likely to be right.
That’s exactly the territory AI recommendation is now entering — the consideration set problem. If I ask an LLM to find me a reliable accountant for a small business, I’m not asking it to retrieve a blog post. I’m asking it to build me a shortlist.
Unlike traditional search, the recommendation layer is invisible to brands unless they test for it actively. You don’t see the prompt or the source chain. You don’t even know why one brand made the cut and another didn’t.
But the commercial effect is real, possibly stronger than anything traditional search produced. If you’re in the recommendation set, you’re in the running. If you’re absent, you’ve lost the sale before the conversation started.
Dig deeper: Rand Fishkin proved AI recommendations are inconsistent – here’s why and how to fix it
The first practical consequence: your website can no longer function like a polite digital brochure. Despite being optimized for search, many commercial web pages simply:
Still, they’re weak where it matters most: actual selling.
In the Mad Men era of SEO, your landing pages and service pages need to function like sales pages, not in a cheesy direct-response way, but in the strategic sense that they must clearly answer four things:
This comes down to positioning, which is key to GEO. If seven brands do broadly the same thing, the model needs distinctions. It needs enough clarity to say: this brand is best for X kind of buyer with Y kind of problem because it does Z better than everyone else.
Your website copy must surface real performance attributes: the specific things you genuinely do better or more distinctively than competitors. Your pages must become machine-readable arguments for preference.
Actual commercial copywriting — not fluffy brand storytelling or word count for its own sake — identifies a target customer, sharpens the problem, articulates the value, and makes the offer easy to recommend.
Good copy isn’t optional.
Take a local sandwich shop. The old SEO conversation runs to “best sandwich near me,” local pack, and review acquisition. It’s useful, but limited.
The GEO version starts with the shop’s actual performance attributes.
Those claims must be clear on the website first. Then they need corroboration everywhere else:
They’re specific, repeated, retrievable evidence of why this shop is the right recommendation for a particular type of customer.
Scale that logic to a B2B software company, and the principle holds. Pages that clearly explain who the product is for, which problems it solves, and why it outperforms rivals. Then build mentions, customer reviews, and gain trade-press coverage — the body of evidence to support recommending you to buyers — and let the AI find it.
That’s pretty much GEO in a nutshell.
Keywords are a human workaround. Approximations of intent, built for a retrieval system that needed exact string matching. LLMs process fuller context, layered needs, and comparative requirements. They move from keyword matching toward problem understanding.
Keyword research still matters for classic search, paid search, and buyer-intent pages. But the center of gravity shifts.
Instead of asking only “what terms should we rank for?”, the better question is: what attributes make us the right recommendation for the buyer we actually want, and what evidence exists across the web to support that claim?
The future of SEO is starting to look like the old agency model, as the work is increasingly promotional. Once your website clearly expresses your positioning, the challenge becomes promoting that position across the wider web through credible, repeated, relevant signals.
These are the things you go after, create, and encourage. Sadly, many “AI visibility” conversations flatten this into nonsense.
The goal isn’t merely to have content cited by AI. It’s to gather enough market evidence that AI systems repeatedly encounter your brand in the right contexts, with the right associations.
The work stops being optimization and becomes maximization: building the largest possible volume of persuasive, corroborated, retrievable evidence that your brand is a sensible recommendation for a specific kind of buyer.
That’s a fundamentally different model from anything the SEO industry has been selling. It’s promotional and strategic brand marketing.
Dig deeper: How to design content that AI systems prefer and promote
SEOs need to grow up. There’s still significant value in buyer-intent search, technical site architecture, entity clarity, internal linking, and structured data. SEOs are well placed to monitor recommendation environments, test prompts, and identify where visibility is being won or lost.
But the identity crisis is real. Many agencies were built for a world of rankings, informational blogs, and monthly traffic graphs. They aren’t equipped to lead a world defined by positioning, copy, PR, brand evidence, and recommendation science.
Tracking brand citations inside AI outputs isn’t a complete strategy. It’s a temporary metric.
Winning agencies look like hybrid commercial strategy firms: part SEO, part copywriting, part PR, part brand strategy, part technical infrastructure. They know how to protect buyer-intent search revenue today while building the fame, clarity, and corroborated authority that earns recommendation tomorrow.
This is the Mad Men model of SEO. Persuasion, positioning, and clear claims backed by public proof matter again. And the job is to become recommended by AI.



















Google explains why it doesn't matter if websites are getting heavier and the takeaway has everything to do with SEO.
The post Google Explains Why It Doesn’t Matter That Websites Are Getting Larger appeared first on Search Engine Journal.

I’m getting a mid-career executive MBA. Last week, in class, we discussed the interaction between automation and advertising. The lecture covered why A/B testing in Meta is less valuable now, since Facebook can auto-optimize faster and better than marketers can on their own.
A classmate took the logical leap and asked the professor, “If digital channels have more data and more processing power, why don’t advertisers just give them a URL and a credit card and let them go wild?”
The argument has real merit. Google, Meta, and LinkedIn have access to more data than any agency ever will. Their optimization engines are improving fast. Handing them a budget and a URL and walking away isn’t entirely crazy.
But that means we’d need to have faith in the channels to optimize media in a business’s best interests, and there’s a long, proud history of that not being the case.
About six years ago, we met with a Google rep who pitched a product that introduced broader, more aggressive targeting and bidding. We listened to the pitch and said no. We didn’t want to try it. The reps turned it on anyway.
What happened next was what we predicted. The campaigns spent significantly more money and didn’t generate any additional conversions.
We had to comp the client for the wasted spend, which was bad enough. But what made it worse was the principle of the thing: we hadn’t agreed to this. Google made unauthorized changes to our account.
When I tried to get the money back, Google’s position was that we’d set our campaign budgets at a certain level, and they were within their rights to spend up to that amount. That framing ignores that a budget cap is a ceiling, not an invitation.
Our agency methodology is to never hit a budget cap. We set those numbers based on the strategy we’d approved, not the one they decided to test. I hounded them for weeks, but never got any resolution. It still makes me angry.
The reps were clearly incentivized to get adoption of the new feature. When it didn’t work, there was no accountability and no recourse. We were left covering the cost of a decision we explicitly declined.
Budget caps were treated as implicit consent to spend. A product we declined was activated without authorization, and when it failed, the platform pointed to our own settings as justification.
The incentive structure rewarded the reps for turning it on. There was no corresponding mechanism to make the advertiser whole when it didn’t work.
Dig deeper: Google rep’s unauthorized ad changes spark advertiser concerns
This was years ago for a successful retainer. A pair of senior Google reps sat across from us and asked what our client’s gross margin was. Around 50%, we said. They went to the whiteboard and wrote out: if overall revenue/2 – overall media cost >= 0, then we should keep spending money on ads.
On the surface, the math sounds right. In practice, it has two problems.
The model treats all reported conversions as incremental and assumes cost per conversion is constant across spend levels. Both assumptions are wrong, and together they can justify significant overspend.
This one still happens all the time. The pitch is that if you raise your CPCs, you’ll get access to higher-quality traffic. The implied logic is that conversion rate is influenced by CPC, and that if your investment isn’t high enough, you’re missing the best clicks.
There’s a version of this that has some truth to it. Higher CPCs can mean higher ad positions, which can mean higher impression frequency against the same users. More frequency can drive higher aggregate conversion rates, because repeated exposure matters.
But the argument glosses over the other side of that equation.
In practice, raising CPCs to chase quality traffic is almost always correlated with substantially worse overall return on ad spend.
This is a variant of the marginal return problem seen across these cases. The pitch frames the upside without acknowledging the cost curve. More spend gets positioned as access to better outcomes, when it often delivers the same outcomes at a higher price.
CPC and conversion rate are presented as if higher bids unlock better traffic. In most cases, the incremental cost outpaces the incremental return. The pitch frames diminishing returns as an opportunity, rather than a constraint.
Dig deeper: Dealing with Google Ads frustrations: Poor support, suspensions, rising costs
“If your Meta campaigns are underperforming, it’s because the algorithm just needs more time to learn.”
“Don’t make changes, and don’t reduce budget, just give the platform more data.”
This is sometimes true. Machine learning systems need volume to optimize effectively, and premature intervention can reset progress.
But “it needs to learn” has become a catch-all explanation that’s almost impossible to disprove in the short run. It explains away poor CPAs, delays accountability, and keeps spend flowing when a reasonable advertiser might otherwise pull back and reassess.
There’s rarely a clear definition of when the learning phase ends, which makes it a moving target. The learning phase ends when performance improves. If performance doesn’t improve, more learning is prescribed.
A real technical concept is being used in ways that resist falsification. When there’s no defined endpoint and no stated criteria for success, “it needs to learn” serves as a blank check for budgetary continuity.
In many cases, YouTube or display campaigns aren’t driving measurable conversions. The rep’s suggestion: let’s look at brand measurement. We can measure recall rates, positive sentiment, and intent to purchase. These are real signals of brand health, and they matter in the long run.
But the shift from conversion to sentiment metrics tends to occur when conversion metrics are poor, not as a principled measurement strategy. Brand lift surveys measure awareness under controlled conditions, but they rely on self-reported intent and don’t connect to downstream revenue.
Recall is almost never translated into a cost per point of lift that can be compared across the media plan. You end up with a number that’s positive and presented as evidence of success, with no agreed-upon framework for what sufficient lift would look like.
A softer metric is substituted for a harder one after the harder one fails. Brand lift is a legitimate measurement tool when defined upfront as a success criterion. Introduced afterward, it functions as a consolation prize.
Dig deeper: PPC mistakes that humble even experienced marketers
Upper-funnel and lower-funnel campaigns serve different purposes and perform differently on a cost-per-acquisition basis. When a channel reports blended CPA across all campaign types, an average that looks acceptable can hide the fact that some portion of the media plan is wildly inefficient at the margin.
The argument for blending is that upper-funnel spend creates the conditions for lower-funnel performance. That is plausible, but plausibility isn’t the same as demonstrated causality.
Often, it’s assumed the upper funnel is directly contributing and that, in aggregate, the system is profitable and fully incremental. This is never the case.
Aggregate CPA can look fine while specific segments of spend have no measurable return. Blending is a reporting choice, and it can obscure where money is and isn’t working.
A view-through conversion is counted when a user sees an ad, doesn’t click it, and then converts within some attribution window, often 24 hours or more. Platforms report these alongside click-through conversions by default.
For retargeting campaigns, which by definition serve ads to people who have already visited your site, view-through attribution is particularly problematic. These users were likely going to return and convert regardless. The ad may have had nothing to do with it.
The issue isn’t that view-throughs aren’t meaningful. For a cold audience, some brand-influenced conversions happen without clicks.
The issue is that those conversions are almost never broken out proactively (you have to ask). And when you remove view-throughs from retargeting campaigns, the ROAS numbers can change dramatically.
We’ve seen cases where removing VTAs cuts reported conversions by more than half. I would note that by moving to incremental measurement options, Meta has become substantially more transparent.
View-through conversions inflate reported performance, particularly in retargeting, where incrementality is already low. Default reporting includes them without flagging the methodological problem.
Dig deeper: Outsmarting Google Ads: Insider strategies to navigate changes like a pro
This one is a pattern. A channel rep brings industry benchmark data to a meeting showing that your competitors are spending at a level above your current budget. The implication is clear: you’re being outspent, and you should close the gap.
Industry benchmarks are among the most valuable inputs a channel can provide. Knowing where you sit relative to the market is useful context for planning. The problem is how they get deployed. More often than not, benchmark data shows up as a tool to expand media spend, not as a neutral input into strategy.
And it works. CEOs and CMOs are particularly susceptible to this framing. Nobody wants to hear that a competitor is outspending them.
The emotional pull of “they’re investing more than you” is hard to counter with a measured conversation about marginal returns or strategic fit. The benchmark becomes the argument, and the argument is almost always “spend more.”
What gets lost is any discussion of whether:
Competitive spend data without context is just a number that makes your budget feel inadequate.
Benchmark data is real, but it’s selectively introduced to justify budget increases rather than treated as one input among many. The framing skips over whether the comparison is meaningful and relies on competitive anxiety to sell.
This one is hard to frame as a single incident because it’s everywhere. I’ve talked to so many people trying to break into the industry, or launch their first campaigns, and the story is almost always the same.
They follow the platform’s setup guide, accept the default settings, and end up opted into programs that have close to zero chance of being successful.
This is true across pretty much every major channel.
Each of these defaults, taken individually, could be defended as a reasonable starting point. Taken together, they create a setup that maximizes the platform’s revenue from day one, before the advertiser knows what’s happening.
A new advertiser following the guided setup is accepting a configuration that the platform designed, and the platform’s incentives aren’t aligned with efficient spend.
This one is genuinely difficult to solve. Platforms need to provide default settings, and they can’t expect every new advertiser to understand every option.
But there’s something predatory about the gap between what people think they’re signing up for and what they’re getting. The defaults are revenue-optimized for the channel, not performance-optimized for the advertiser.
Setup guides and default settings are presented as best practices when they’re actually configurations that favor the platform’s revenue. New advertisers trust the guided experience, and have no reason to suspect the defaults are working against them.
Dig deeper: Are you being manipulated by Google Ads?
Privacy regulations and platform changes have created real limitations in conversion tracking. GDPR and Apple’s App Tracking Transparency aren’t invented problems.
We have less visibility than we used to, and the platforms have responded by layering probabilistic modeling and modeled conversions on top of deterministic tracking.
But the tracking gap has also become a convenient shelter for underperformance. The argument goes like this:
Each of those can be true in isolation. Modeled conversions take time to appear. Attribution is harder than it was five years ago. Proxy metrics can be useful when direct measurement breaks down.
The problem is when all of these caveats get stacked together and used to justify sustained spend in the absence of any measurable result. At some point, “the data will come in” stops being a reasonable expectation and becomes an article of faith.
The tracking gap is real, but it cuts both ways. If you can’t measure the result, you also can’t prove the spend is working. The platform’s default position is to assume it is, and keep going. The advertiser’s job is to ask what happens if the modeled conversions never materialize, and what the fallback plan looks like if they don’t.
Legitimate tracking limitations are used to defer accountability indefinitely. When measurement is hard, the platform’s recommendation is always to maintain or increase spend, never to reduce it. The uncertainty gets resolved in the channel’s favor by default.
None of this is an argument that agencies are irreplaceable in their current form. We used to question tCPA, and now it’s a preferred bidding strategy. Automation handles execution-level work that used to require skilled practitioners. In-house teams are viable for more companies than they used to be.
But the argument for fully autonomous, channel-run advertising assumes the channel will optimize for your outcomes rather than revenue. Even if we imagine new profit-sharing contracts, this assumption carries real risk.
And I’m not blaming reps or the channels. They believe in their products, but they’re also measured on metrics that create a predictable drift in how they frame data. I should note that agencies struggle with misaligned incentives as well.
The advertiser’s job, with or without an agency, is to keep asking the inconvenient questions.
Maybe the answer to everything is eventually full automation. But the entity building the machine shouldn’t be the one telling you when it’s ready.

For years, Salesforce Marketing Cloud was the safe choice.
Powerful. Enterprise. Trusted.
But lately, we’re hearing something different:
Sound familiar? If so, this fireside chat is for you.
We’ve helped dozens of brands migrate off Salesforce and into modern, composable engagement architectures built for real CRM performance. Not because it’s trendy — but because marketers needed more speed, flexibility, and innovation.
In this April 14 session, we’ll cover:
To be clear: this isn’t a Salesforce-bashing session.
It’s a candid conversation about innovation velocity, marketing ownership, and what the next era of marketing actually requires.
Disclaimer: To ensure a candid and open conversation, the live session is open only to brand-side marketing leaders. Registrants who are not verified brand-side marketing leaders will not be permitted to attend the live session. However, the recorded session will be made available to all registrants upon completion of the event.
Intel’s first CPUs to integrate Nvidia graphics chiplets are reportedly called “Serpent Lake”, and they could launch in late 2028 Last year, Intel struck a deal with Nvidia that would allow them to “build and offer to the market x86 system-on-chips (SOCs) that integrate NVIDIA RTX GPU chiplets.” According to the leaker Jaykihn, Intel’s first […]
The post Intel “Serpent Lake” CPUs to integrate Nvidia graphics in 2028/2029 appeared first on OC3D.
























 We’re sharing an update on our mental health work, including some new changes to better connect people with the right information.
We’re sharing an update on our mental health work, including some new changes to better connect people with the right information. STALKER 2 is getting some free content ahead of its Cost og Hope DLC this summer GSC Game World has confirmed that STALKER 2 is getting a free content update this month. This update is “Sealed Truth”, which will allow players inside the X-18 Lab. STALKER fans should already be aware of the Lab X-18, […]
The post STALKER 2 is getting a free content update this month called “Sealed Truth” appeared first on OC3D.









Giraffe Gold lets you build ownership of a physical gold, silver, or platinum bar through small monthly contributions and automatic round-ups. Connect your bank and spending card, set a contribution starting at $50, and watch your bar balance grow in real time with market prices.
When you hit the bar price, Giraffe Gold purchases from certified refiners and ships your bar fully insured to your door. The platform uses Plaid for secure, read-only connectivity and partners with Upstate Coin & Gold and ShipSecure to ensure authenticity and safe delivery.
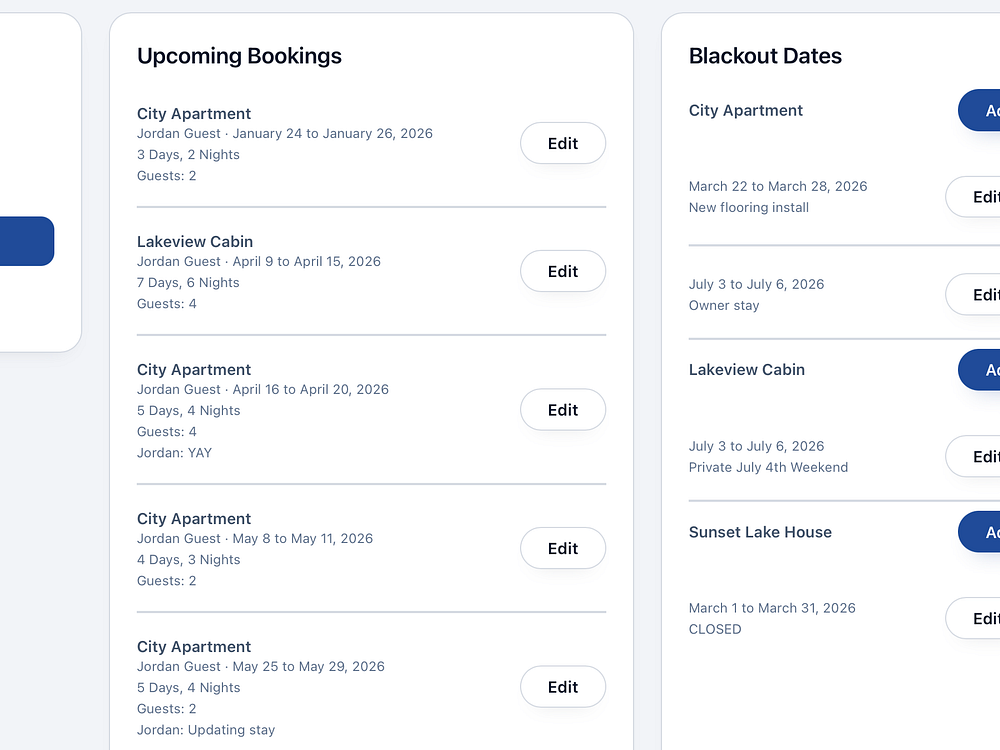
Stay the Week helps homeowners privately share lake houses, cabins, beach houses, ski condos, and second homes with friends and family. Invite guests to a private booking page to see availability, request dates, and receive automatic confirmations and reminders. Owners control availability, blackout dates, and access from a simple dashboard, with directions and property info attached to each booking, replacing messy text threads with a clean, controlled process.




Google's John Mueller says that those who self-identify as SEO gurus are clueless imposters.
The post Google’s Mueller On SEO Gurus Who Are “Clueless Imposters” appeared first on Search Engine Journal.
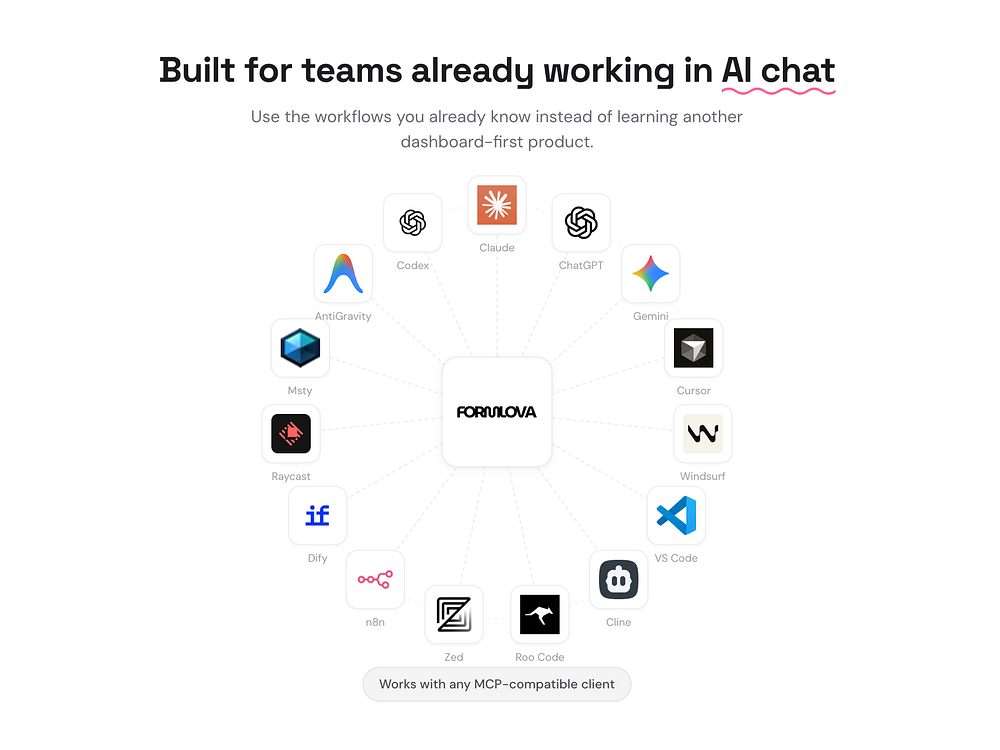
FORMLOVA is a chat-first form service powered by MCP. Create forms from ChatGPT, Claude, or Cursor in under a minute, then manage response routing, follow-up emails, reminders, analytics, and CRM handoffs from the same conversation. It integrates with 118 tools across 24 categories, focusing on the 95% of form work that happens after the form exists.
Most AI form tools stop at creation. FORMLOVA was built by a solo founder with years in digital marketing who knew the real burden was in post-publish operations. It's free to start with unlimited forms and responses.
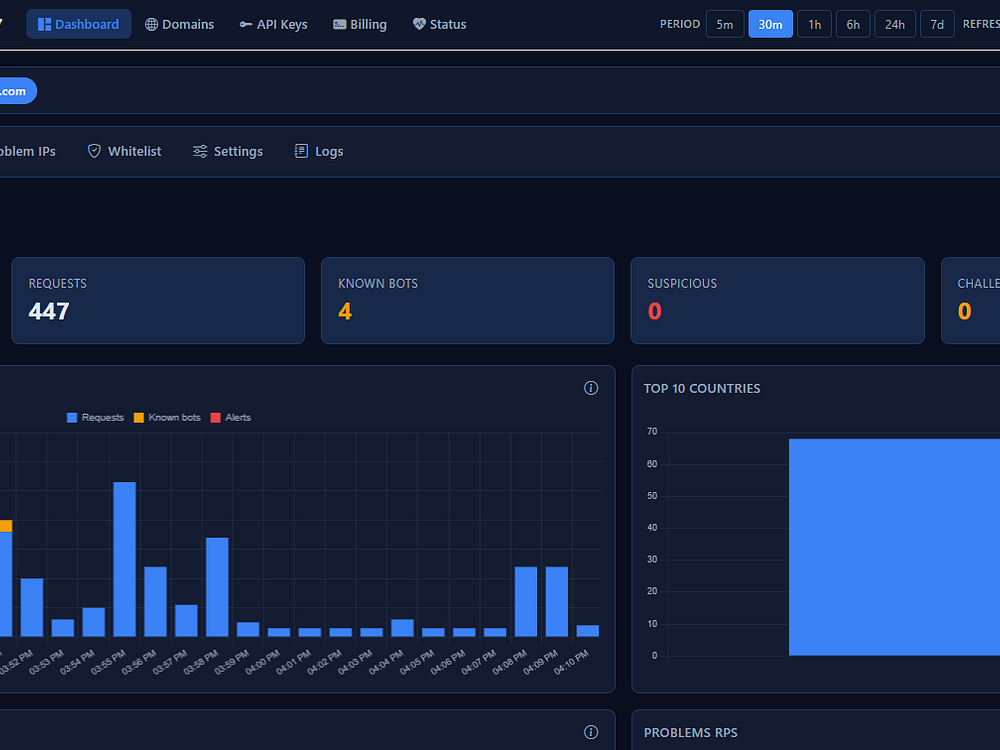
If you're running a website on Cloudflare's free or pro plan and don't have time to babysit logs or tune WAF rules, Detect7 fits. It gives you automated, intelligent protection that works in the background without needing you to be a security expert. You set it up once, and it handles the rest: detecting threats, escalating from challenge to block, learning traffic patterns, and managing Cloudflare firewall rules and IP lists for you. It analyzes 100% of your origin logs in real time, learns your normal patterns, and auto-blocks threats with adaptive rules pushed to your Cloudflare integration.
Battery dying? WiFi gone? Your Mac finally talks back.
Live schedules on the Lock Screen for event crews
Dedicated space to bring your personal health data together
Claude Code as a Tech Lead with parallel Worker Agents
A full navigation utility in ~2MB
Watch 10K+ live flights move on a 3D globe in your browser
Privacy-first AI finance tracker
Studio-grade AI lip sync and visual dubbing
Search, Reach and Connect - Find the perfect fit, 10x faster
data analysis workspace for Claude Code/Codex
Create forms and manage submissions inside ChatGPT
Press Tab for AI anywhere you type on Mac
Letters made of letters
The IDE for video engineers
Get seen in search, AI and beyond
Turn your Mac notch into a native 6-in-1 command center
Know when your automations run, fail, or go quiet.
Real-time subtitles, translation, and dictation for Mac
Track body measurements, fat%, lean Mass, progress & more
Grow your vocabulary while you browse the web
AI-native data catalog with search, lineage and MCP
A world for kids to explore along their favorite characters
The AI co-author for research papers
Select any screen area, get text instantly
A faster, simpler alternative to bulky VM managers.
A night-vision smart camera that knows when you are dreaming
AI architectural renders and interior design
Connect AI agents to browser through raw CDP
AI ensemble that scored #1 on Humanity's Last Exam
Record your microphone, system audio simultaneously
Smart dictation, AI assistant, + app control via voice
A cozy productivity app to focus with others + vibe to lofi
Your online couch for movies, games, and good times
The intelligence layer for ChatGPT Ads
Automate what APIs can't in one prompt done locally
Fix your terrible posture
App store connect data + subscription insights
Native planetary imaging capture for macOS and Apple Silicon
Ask your Playwright tests why they failed
Give your agent tools to create beautiful, codebase-aware UI
Cinematic UI mockups in the browser
Google's offline-first AI dictation, powered by Gemma
Record, edit, and brand screen recordings Metal powered
Never lose anything you copy again
A mindful way to measure and understand your body activity


Spawnbase turns recurring work into reliable AI-powered workflows. Teams describe goals in plain language, then build agentic flows with triggers, AI steps, and app actions across seven providers and 200+ models. Configure nodes, test each run, and deploy on schedules or events while monitoring performance. Connect Slack, GitHub, HubSpot, Notion, Jira, and more, and pay only for executions with credit-based pricing.


Axe:ploit signs up with its own email and phone, discovers APIs, and probes for over 7,500 issues including IDOR, auth bypass, and complex business logic flaws. Backed by a constantly updated CVE feed, large password and fuzzing datasets, and layout-aware crawling, it adapts as your UI and logic change.

Simmerce lets e-commerce teams run synthetic customer simulations to validate features before launch. It generates diverse shopper personas—budget shoppers, brand loyalists, impulse buyers, and researchers—and simulates how they search, browse, and convert to reveal friction and opportunities. Upload a product pages, search results, or recommendations and get insights in minutes, including which segments convert, where users get stuck, and what content is missing. Use pay-as-you-go credits to test ideas fast and ship with confidence.


Intel Desk connects geopolitical events to market instruments every 30 seconds. It aggregates over 60 OSINT and wire sources, scores sentiment, and maps topics to instruments to surface directional trade signals with evidence trails for energy traders, macro researchers, and defense analysts. Users get live market data via Finnhub, portfolio impact alerts, and twice-daily briefings, with transparent source chains and low-latency delivery you can trace end to end.
TrackACert.io is a simple tool for IT managers who need to know what certifications their team holds, what's about to expire, and where the gaps are. We connect GIAC, CompTIA, ISC², AWS, Microsoft, and more in one place. Key features include IT certification tracking, certification expiry notices for your team, skill gap analysis to identify missing skills and certifications, and full reports to help justify financing for more certifications.


Keyspace delivers AI-powered inventory management and warehouse automation for teams of any size. It connects to your existing tools, monitors stock in real time, and drives decisions on forecasting, replenishment, and operations.
Use collaborative workflows, advanced analytics, and a customizable interface to streamline processes, cut stockouts, and reduce carrying costs while scaling with confidence.
Despite its merger with xAI and the upcoming SpaceX initial public offering in June, running the app is costing Elon Musk more money than it’s bringing in.
The new profile will be used to share Japan-specific information for users as Meta continues to challenge X for dominance in the microcontent sphere.
Adam Mosseri said that reposting feed posts to Stories won’t increase reach.
The company plans to eventually offer open source versions as its Superintelligence group works to catch up with industry benchmarks, per Axios.
The extended partnership gives users of both platforms more tools to manage ad campaigns and measure ROI.









Betvisors connects bettors with verified sports betting advisors and lets you tail their picks with one tap. You only tip when a pick wins; if it loses, you pay nothing. Advisors prove their track records with betslip screenshots, and a public leaderboard shows win rate, profit, and streaks. Gambly integration places bets at your sportsbook instantly, while Stripe handles secure payments. Advisors can monetize winning picks and grow a following on the platform.
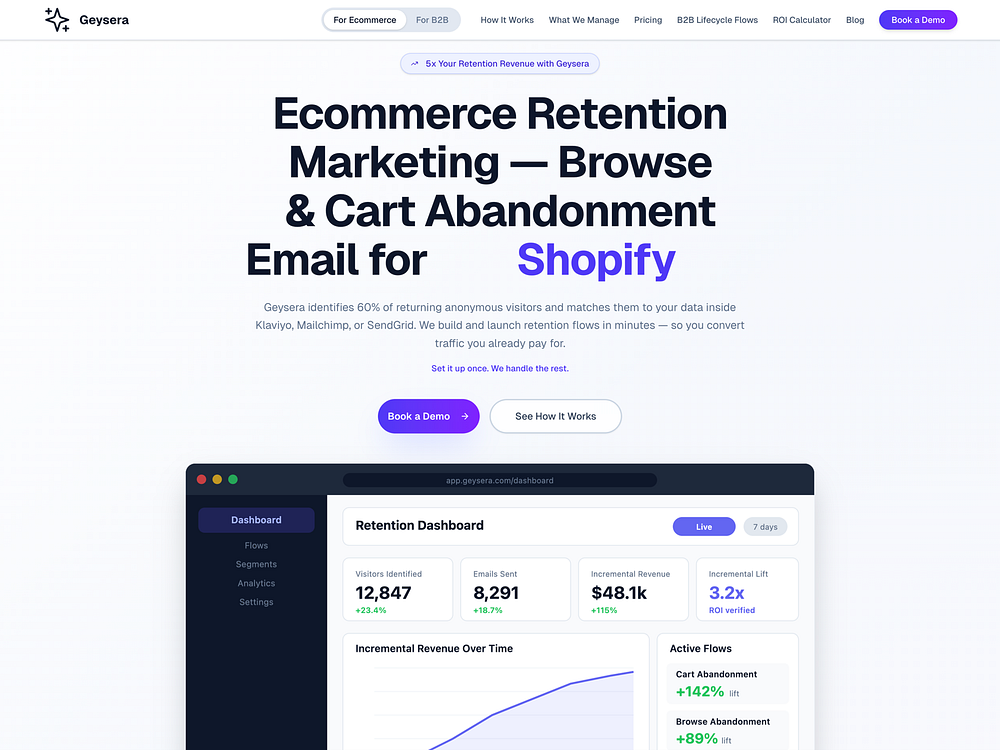
Geysera helps ecommerce brands recover revenue by identifying returning anonymous visitors and syncing them to your ESP. It builds and manages cart, checkout, browse, and winback email flows inside Klaviyo, Mailchimp, or SendGrid, then optimizes continuously within your discount guardrails. Always-on holdout groups and RCTs prove incremental lift, and pricing ties to verified revenue. Brands and agencies get white-glove setup, real-time dashboards, and compliance-aware copy.








An Ipsos survey of U.S. adults found 63% say ads in AI search results would reduce trust. Early advertiser data offers limited, mixed signals.
The post Trust In AI Search Could Drop With Ads, Survey Shows appeared first on Search Engine Journal.

If you rank your own product #1 in “best of” listicles, it’s not just a search-quality issue — it may violate FTC rules that took effect in October 2024.
Driving the news. As Lily Ray noted on LinkedIn, the FTC’s Consumer Review Rule (16 CFR Part 465) prohibits several deceptive practices tied to reviews and testimonials, including:
Penalties can reach up to $53,088 per violation, and each page may count separately. Ray also shared a reference table she generated with the help of Claude:

Why now. “Best X” and “Top 10 Y” listicles have surged as a GEO tactic over the past couple of years. These pages often perform well in search and increasingly influence AI-generated answers.
The backstory. Before the rule was formalized, Ray said at least one company faced legal action for publishing hundreds of “best of” pages that:
The Better Business Bureau later censured the company for unsubstantiated claims.
What’s happening. Many modern listicles follow a similar pattern:
These listicles may imply independence or firsthand evaluation when neither exists.
The nuance. You can publish comparison content that includes your own product. However, based on FTC guidance, risk increases when:
What Google is saying. Google is aware of the low-quality listicle trend. In a statement to The Verge, a Google spokesperson said the company applies protections against manipulation in Search and Gemini, and reiterated its guidance: create content for people and ensure it’s understandable to search systems.
Why we care. What has worked as a visibility tactic may carry risk on two fronts — regulators and a potential Google Search algorithm change. That means this popular GEO tactic could decline quickly as its effectiveness drops.
Caveat. I’m not a lawyer. Consult your own legal counsel if you’re concerned about using this tactic.
Intel preps a huge socket for future CPUs with HUGE graphics chips Intel is reportedly working on a new CPU that aims to challenge AMD’s “Strix Halo” and Apple Silicon. With its huge 4326 socket, Razor Lake AX aims to bring together strong CPU and GPU hardware to deliver a strong single-package computing solution for […]
The post Intel Razor Lake-AX to challenge Apple Silicon appeared first on OC3D.







AI travel companion that generates day-by-day itineraries, then stays with you throughout the trip. Proactive morning briefings, smart packing lists, budget tracking, local insider tips, and a Spotify Wrapped-style trip recap. Free to try.

co-parenting.ai is the AI family app for separated parents — an assistant that communicates and coordinates the logistics, a place for family context, a village hub for grandparents, nannies, and schools, and a dedicated space for kids that shields them from adult conflict. It works whether your co-parent joins or not. We built this for the kids. Every conflict de-escalated means two present parents instead of two stressed ones. Every caregiver and extended family member who shows up knowing the schedule is a child who feels held by a bigger family.

Human-written content dominates Google’s top rankings, appearing in the No. 1 position 80% of the time versus just 9% for purely AI-generated pages, based on a Semrush analysis of 42,000 blog posts.
The details. Semrush analyzed 20,000 keywords and their top 10 results, classifying content with an AI detector.
Yes, but. AI detection tools are widely known to be inconsistent and can misclassify human and AI-written content, creating some possible “fuzziness” in these classifications.
Why we care. AI-generated content works, until it doesn’t. Yes, AI can help you rank, but this data suggests human insight still drives the best performance. For competitive queries, originality, expertise, and editorial judgment remain your unfair advantages.
Perception vs. data. 72% of SEOs said AI content performs as well as or better than human content, yet ranking data showed a clear human advantage at the top.
How teams use AI. No surprise, AI is widely adopted and often used in a hybrid approach:
What’s driving adoption. AI accelerates output, but doesn’t reliably improve it.
About the data: The analysis examined 42,000 blog pages from 200,000 URLs tied to 20,000 keywords, using GPTZero to classify content. It also includes a survey of 224 SEO professionals working in content and search.
The study. Does AI content rank well in search? [Survey + Data study]












MetricSign monitors your Power BI datasets every five minutes and tells you when something breaks, such as a failed refresh, a missing column, or a changed schedule. Each alert includes the exact error, what caused it, and a direct link to fix it in Power BI. It works with ADF, Fabric Pipelines, and Databricks too, so you can see the full chain from source to dashboard. Setup takes two minutes: sign in with Microsoft, pick your workspaces, and you're done.
LLM Pulse helps companies understand how they appear in AI search and how to improve it. We track brand presence across leading LLMs like ChatGPT, Google AI Mode, Gemini, and Perplexity, analyzing prompts, responses, citations, and sentiment. Rather than relying on abstract scores, LLM Pulse shows the actual answers users see, making it easy to spot gaps, understand competitors, and take action through content and technical improvements. Designed for marketing, SEO, and growth teams, it turns AI visibility into something you can measure, understand, and act on.
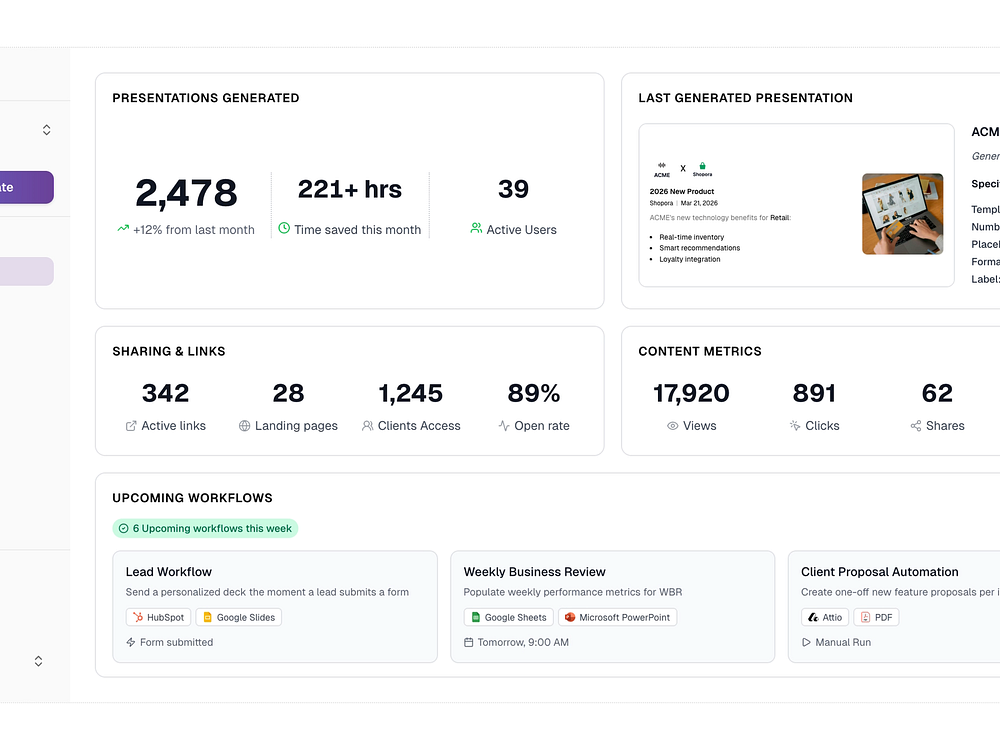
AutoScaled generates personalized presentations directly from your CRM and spreadsheet data using a single prompt. Connect HubSpot, Salesforce, Attio, or your data sheet and specify which records to create tailored presentations for. Upload a template from Google Slides or PowerPoint to build sales decks in seconds.
The AI agent personalizes your content based on your data, maintains brand consistency, and saves you time. You can trigger presentations when CRM data changes, schedule recurring decks, and refresh existing ones with one click. Share content via branded pages, track engagement, and see who viewed what.

In this case study, we went deep instead of broad. We focused on one question: why wasn’t a brand present in a single ChatGPT prompt across ~70 iterations?
We chose one prompt: “What are the best hotels in New York City?”
We analyzed mentions, citations, fanouts, and SERPs in Google and Bing. We also planned to analyze GPT memory, but it made no discernible difference to mentions, citations, or fanouts.
We chose NYC hotels because it’s a crowded, mature market with juggernauts and up-and-comers. We also have no connection to the NYC luxury hotel space — we intentionally picked an area where we could stay objective and learn from scratch.
After running the prompt “what are the best hotels in New York City” 68 times, we identified which hotels appeared most consistently and which were nearly invisible.
We chose the Baccarat Hotel as our “client” because it appeared only once (1.5% of the time), despite strong reviews and clear alignment with the prompt’s intent. We wanted to know why — and whether it could change that.
Key findings:
Note: A full methodology breakdown appears in the appendix.
The Baccarat Hotel appeared once in 68 trials (1.5%).
Top performers were large luxury hotels like the Four Seasons Hotel New York Downtown.
ChatGPT also identified boutique hotels as a subcategory, generating a secondary list in its answers. Boutique hotels like the Baccarat are typically smaller and not part of large chains.
Within this boutique subcategory, the Baccarat still underperformed. The Fifth Avenue Hotel, the top-performing boutique property, appeared 13 times, cited 20% of the time, versus the Baccarat’s 1.5%.
We first checked whether anything in the hotel’s history or reputation could explain the gap. As the chart below shows, nothing significant did:
| The Baccarat | The Fifth Avenue | |
| Year Founded | 2015 | 2023 |
| Current Price | $930 | $563 |
| Number of Google Reviews | 1.3k | 213 |
| Google Reviews Rating | 4.6 | 4.6 |
| Number of Expedia Reviews | 531 | 201 |
| Expedia Reviews Rating | 9.4 | 9.6 |
Overall, the Baccarat has been around longer and has more reviews. On quality, the Fifth Avenue Hotel has no edge in Google reviews and only a slight edge in Expedia reviews. The only area where the Baccarat lags is price — but that’s unlikely the issue when The Ritz-Carlton, a consistent non-boutique winner, is listed at $1,100.
Further reinforcing the Fifth Avenue’s underdog status: one of its most prominent Google results (rank 2) was a Wikipedia page for a different Fifth Avenue Hotel that closed in 1908, creating potential entity confusion similar to the two Danny Goodwins.
If the Fifth Avenue Hotel had been the one missing, it would suggest a less established brand with entity confusion. But the opposite happened — it prevailed in ChatGPT.
So what was the problem for the Baccarat Hotel?
When ChatGPT performs a web search, it sends a series of queries you can extract via Chrome DevTools. In this case study, examples included:
In total, we extracted 25 unique query fanouts.
If we only looked at the articles dominating fanout SERPs in Google, we’d expect the Baccarat to narrowly outperform the Fifth Avenue in ChatGPT. That didn’t happen.
In the table below, the Baccarat “wins” three of the top 10 most frequently appearing pages, while the Fifth Avenue Hotel “wins” two. The other five feature neither. A “win” means one of the following:
The data:
| URL | Who Wins? | Notes |
| https://www.forbestravelguide.com/destinations/new-york-city-new-york | The Baccarat | The Baccarat Hotel is #4 on the list, the Fifth Avenue Hotel is #13 and sits far below the fold |
| https://www.mrandmrssmith.com/destinations/new-york-state/new-york/hotels | Neither | Neither Hotel appears on this list |
| https://guide.michelin.com/us/en/article/travel/the-best-hotels-in-new-york-all-the-michelin-key-hotels-in-the-city | The Fifth Avenue | The Baccarat is listed as a “one key” hotel, placing it at the bottom of the list. The Fifth Avenue Hotel is listed as a “two key” hotel, placing it in the middle of the list. |
| https://youshouldgohere.com/2025/01/best-boutique-hotels-new-york-city/ | Neither | Neither Hotel appears on this list |
| https://travel.usnews.com/hotels/new_york_ny/ | The Baccarat | The Baccarat #11 on the list, the Fifth Avenue Hotel #16 |
| https://luxlifelondon.com/best-hotels-manhattan-new-york-city/ | Neither | Neither appears on this list |
| https://www.tripadvisor.com/Hotels-g60763-New_York_City_New_York-Hotels.html | Neither | Neither Hotel appears on this list |
| https://www.lartisien.com/hotels/united-states/new-york | The Baccarat | The Baccarat is #5, the Fifth Avenue is #15 |
| https://www.cntraveler.com/gallery/readers-choice-awards-new-york-city-hotels | Neither | Neither Hotel appears on this list |
| https://www.reddit.com/r/chubbytravel/comments/1n7jro1/which_luxe_hotels_are_people_loving_in_new_york/ | The Fifth Avenue | Both mentioned, but the Fifth Avenue much more positively |
By contrast, looking only at the articles dominating fanout SERPs in Bing, we’d expect the Fifth Avenue to outperform the Baccarat in ChatGPT — and it did.
In the table below, the Fifth Avenue “wins” five of the eight most frequently appearing URLs.
Note: The table includes two fewer URLs because Bing SERPs were slightly less diverse for these fanouts.
The data:
| URL | Who Wins? | Notes |
| https://www.forbes.com/sites/forbes-personal-shopper/article/best-hotels-in-new-york-city/ | Neither | Neither appears on this list |
| https://www.timeout.com/newyork/hotels/best-luxury-hotels-in-nyc | The Fifth Avenue | The Fifth Avenue is #1, The Baccarat is #16 |
| https://robbreport.com/travel/hotels/lists/best-luxury-hotels-new-york-city-1237348563/ | The Fifth Avenue | The Fifth Avenue is #5 (but also wins the hero image/caption), the Baccarat is #11 |
| https://www.cntraveler.com/story/best-boutique-hotels-nyc | The Fifth Avenue | The Fifth Avenue appears, the Baccarat does not |
| https://www.travelandleisure.com/best-hotels-in-new-york-city-8612778 | The Baccarat | The Baccarat appears, the Fifth Avenue does not |
| https://www.tripadvisor.com/Hotels-g60763-zff12-New_York_City_New_York-Hotels.html | The Fifth Avenue | The Fifth Avenue appears, the Baccarat does not |
| https://www.cntraveler.com/gallery/best-hotels-in-new-york-city | The Fifth Avenue | Both are listed, but the Fifth Avenue is listed under “Our Top Picks” |
| https://travel.usnews.com/hotels/new_york_ny/ | The Baccarat | The Baccarat is #11 on the list, the Fifth Avenue is #16 |
Bing rank strongly predicts ChatGPT citations — 87% align with Bing’s top results, Seer Interactive found. Our case study supports this and extends it.
We examined the relationship between fanouts (Seer focused on prompts) and brand mentions.
Example mention: “For a luxury boutique feel: listings like The Fifth Avenue Hotel or Crosby Street Hotel consistently make ‘top NYC’ lists from travel editors.”
Mentions are often more valuable than citations. Most people won’t follow citations but will remember the top recommendation.
There’s ongoing debate about whether fanouts shape ChatGPT’s answers and mentions, or simply support answers generated from training data. For example, Leigh McKenzie argued on LinkedIn:
By contrast, our data aligns with Beehiiv’s research, which suggests citations do shape mentions.
Training data doesn’t appear to be the issue for the Baccarat. Compared to the Fifth Avenue, it’s older, has more reviews, and holds similarly high ratings across major platforms. What it lacks is strong presence in Bing results for fanouts and citations, which appears to lead to fewer mentions.
A simple flow might look like this:
In this vertical, third parties like Forbes and Condé Nast control the space. Visibility depends on who mentions you, so you need a strong outreach strategy — not just updates to your own content.
Our data shows that “targeting Forbes” isn’t specific enough.
The top result surfaced in both Bing and ChatGPT was the same Forbes article. In Google, the most frequent fanout result was also a Forbes article — but a different one.
As we’ve seen, getting into Google’s Forbes article likely wouldn’t provide a meaningful boost. The Baccarat “won” in that piece.
Getting into Bing’s Forbes article, where the Baccarat wasn’t mentioned, could make all the difference. This requires a highly surgical approach grounded in Bing data.
Generalities won’t work; detail reigns supreme.
Model: We prompted GPT-5.2 Instant and manually extracted results. We didn’t use APIs within ChatGPT.
Number of iterations: We ran the same prompt 68 times.
Prompt: “What are the best hotels in New York City?”
Settings: We tested three memory states:
For all trials, we turned off “reference chat history” to avoid interference across iterations.
We expected differences based on memory settings but found none, so we treated all trials as a single dataset.
What we extracted:










Is it possible to get an accurate view of the current state of SEO?
There have been multiple attempts to reach consensus on what works, predict what might be coming, and identify the factors that may play a role in “good” (or “bad”) SEO.
As useful and productive as some of this may be, none of it offers the same grounded data as the Web Almanac, a project I was honored to be a part of. With the publication of the 2025 SEO chapter, we can now review the data and spot the emerging trends from 2025 and what that could mean for SEO in 2026.
2025 has been another year of increasingly higher SEO standards — which can only be a good thing:
Not all of these statistics represent rapid change, but they do show steady and consistent change, at the very least. The 2025 Web Almanac data presents the web as a more secure and easier-to-crawl place, which is certainly a positive.
So, can SEOs take a victory lap right now? No, as there is more to do in 2026, even if the basics do feel like they’re stable or steadily improving.
Content management systems (CMSs) and SEO plugins play a huge role in developing SEO best practices and cementing the “default” or de facto standards.
As the CMS chapter in the 2025 Web Almanac shows, more and more websites are now powered by a CMS:

Of these, the top five most popular systems over the last four years likely aren’t surprising.

Frequently underpinning many SEO defaults are SEO tools typically utilized by WordPress sites:

That’s not to say that using these platforms or tools ensures a perfect website setup. That said, key elements or functions of these tools can become industry standard due to their ubiquity:
Not all of these are on by default. Sometimes they require inputting basic details or simple implementation. Regardless, their ease of access increases the likelihood that they will become an SEO best practice.
This is happening, and it’s proving effective. What this means for 2026 and beyond is that:
Defaults and best practices help, but they don’t finish the job. While attention often shifts to new features, old or forgotten standards still see widespread use.
There have been many different cases where deprecated settings or standards have prominently appeared in the data.
Web changes — no matter how small — are often neither quick nor easy to get done, and we’ll likely see traces of deprecated features and settings in the data for years to come.
The improvement in SEO standards doesn’t apply to all features and sites. There are some that aren’t moving in the same direction:
While CMS default settings or configurations can take credit for some of the larger changes, they also bear some of the responsibility for the issues above. For example, median Lighthouse scores for some of the major CMS platforms are still lagging, especially on mobile (while seeing increases over last year).

The long tail of the web is still messy, and this will probably always be the case. The Web Almanac dataset doesn’t exclude websites that are no longer relevant or abandoned.
Site metrics that meet the “top” standards from an SEO best practices point of view can likely be achieved with an out-of-the-box site built on any major CMS with a modern theme and 30 mins of carefully considered configuration. This is one of the most significant opportunities in technical SEO.
In 2026, we’ll likely:
One of the more eagerly awaited elements of the Web Almanac data was whether we can chart the increasing presence and impact of AI search and crawlers in the decisions of SEOs and developers.
Within the data, we observed two major developments:
Commenting on the state of SEO is challenging because the definition isn’t fixed. What’s good or bad practice is often hotly debated, and in the world of AI search, another (painful) metamorphosis is now taking place.
In the HTTP Archive data we can observe the influences working on SEO from a “nuts and bolts” point of view, report on what we see, and enable people to make up their own minds.
Specifically, one of the elements we added this year was the analysis of the llms.txt file.
This is a highly controversial text file, but our inclusion was not an endorsement. It’s a recognition that changing trends may (or may not) shape the web. Whether it’s effective or accepted, its adoption says something, and we felt it was important to review that.
It’s clear that robots.txt has a more important job now than ever. Until relatively recently, it was largely used for targeted control of crawlers, particularly Googlebot and Bingbot.
For most SEOs, however, robots.txt was mostly an exercise in both ensuring we weren’t blocking anything by accident and resolving problem areas with Disallow rules. This has changed:
Robots.txt isn’t the only way to manage bots — and arguably isn’t the best — but it introduces a new decision that must be made: How should websites handle LLM crawlbots?
This will be one of the biggest areas we’ll see change in on the technical side of 2026:
In 2026, SEOs will be drawn into bot management conversations spanning marketing, technology, and security. “Which bots should we allow?” is a question with downstream effects on budgets, revenue, and users, and we’ll need to closely monitor what develops.
LLMs.txt is an aspiring web standard that aims to guide LLM crawlbot behavior and make it easier for them to retrieve content before generating an answer. It’s a highly controversial .txt file, and there’s a vigorous debate on whether it actually benefits LLMs, will gain widespread use, and is a possible vector for manipulation.
The rationale or efficacy of this file isn’t something we need to cover here. For this article, the true point of interest with llms.txt is the adoption of this file as a statement of intent.
At the start of 2025, I crawled the Majestic Million, a regularly updated list of the top 1 million websites ranked by backlink authority, in search of llms.txt and found that adoption was extremely low (0.015% of sites, or just 15).
While searching one million sites versus 16 million presents some logistical differences, I was expecting a very low level of adoption based on prior experience. I was surprised at how wrong I was.
According to the 2025 data, just over 2% of sites had a valid llms.txt file, and:
This number is still relatively low, but it’s much higher than I thought it would be and potentially represents a huge acceleration.
The primary reason fueling adoption of llms.txt’s SEO plugins that make this easier to enable.
We can see that llms.txt adoption has continued to rise ever since we started collecting data from across the web:

If, however, the implementation of this file is actually a default feature in some scenarios, it could be easy to overvalue its significance.
LLMs.txt will still be a barometer of AI search decision-making in 2026:
Another interesting trend worth discussing is the increase in the use of the FAQPage schema.
While this isn’t as explicit a trend as robots.txt or llms.txt usage, the increased adoption of this schema type is particularly interesting.
Since Google said it was limiting the appearance of FAQ snippets in search results, you’d be forgiven for thinking the implementation of this schema type might plateau — or even fall.
However, you can see from the last three publications of the Web Almanac that this isn’t the case:

The use of FAQPage schema is now an emerging trend as AI search heavily cites FAQ content in its outputs.
This could be correlation rather than causation, but the steady increase in FAQPage schema is a strong sign of AI search strategies changing the shape of the web.
To echo another conclusion from earlier, 2026 may well see continued growth of structured data types even if they don’t result in an obvious improvement. While the growth is unlikely to be explosive, making a case for their implementation is easier when we don’t just optimize for Google.
Will AI search reshape the web in 2026? Unlikely. Will we continue to see signs of its importance? Almost certainly, but let’s not get carried away.
SEO has a reputation for changing quickly. Sometimes that’s true. More often, it’s the conversation that moves quickly, while the web itself changes at a steadier pace.
The 2025 Web Almanac data clearly reflects that tension. Core SEO hygiene continues to improve year over year, but largely through default features and settings, tools, and platform behavior rather than deliberate optimization.
At the same time, long-deprecated standards linger, advanced configurations remain uneven, and the long tail of the web remains untidy. Progress is real, but it’s incremental — and sometimes accidental.
What has shifted meaningfully is intent.
2026 will not be remembered as the year SEO ended or was reborn. It may, however, be considered the year the AI search layer became more defined. A new patch applied — not a fundamental rewriting.
For a deeper dive into the data behind these trends, explore the 2025 Web Almanac SEO chapter.

Most guidance on optimizing for AI still focuses on how content is written. But AI systems don’t read content the way humans do. These systems extract information, break it into parts, and reuse it in new contexts. What matters is whether your content can be pulled into an AI-sourced answer cleanly.
Where traditional SEO has centered on ranking pages, AI systems prioritize retrievable units of meaning. That changes how content needs to be built:
The shift is structural: Content that performs well in this environment is designed to be extracted, recombined, and attributed.
To design for AI usefulness and visibility, you need a basic model of how content is selected and used.
AI systems segment content into passages and retrieve those independently. That has a few implications:
When structure is unclear, the signal becomes less reliable, even when the topic is relevant.
After retrieval, content is used to generate an answer. AI systems tend to favor passages that:
This is where “low-edit distance” shows up in practice. Content that can be used as-is has an advantage.
AI systems also decide what to cite. Content is more likely to be attributed when it includes:
If a section reads like a generic summary, it’s easier to replace with another source.
When content is retrieved in pieces, used in generated answers, and selectively attributed, structure becomes the lever. These principles show up consistently in content that gets surfaced by AI systems:
Content is more useful when it’s built in discrete units. Each section should:
Long sections that depend on earlier context are harder to reuse in isolation. Modular structure also makes content easier to update, test, and repurpose across surfaces — without rewriting the entire page.
A clear hierarchy helps systems understand what each section contains and how it relates to the rest of the page. H2 → H3 → H4 structure should signal:
Headings should make each section’s purpose immediately clear. When that signal is weak, it becomes harder to match the right section to the right query.
AI systems rely on what’s stated directly. Make relationships and conclusions clear by:
If something is important, it should be written plainly. Copy that requires inference is harder to interpret and more likely to be skipped in favor of clearer alternatives.
Place the direct answer to the section’s core question at the top, then expand.
AI systems prioritize passages that resolve a query immediately. When the answer is delayed or embedded within a longer explanation, the relevance of that passage becomes less obvious.
Answer-first formatting requires that the opening lines:
The rest of the section can then add deeper nuance, examples, or other details that further understanding without changing the core response.
Passages compete for selection, both within the same article and across the web.
When multiple sections address the same question in similar ways, they dilute each other. Clear, specific, and well-scoped content “chunks” are more likely to be selected.
You can audit a passage’s usefulness by asking:
If the passage needs context or cleanup, it’s less competitive.
These patterns show how structured, answer-first content is applied in practice — making it easier for AI systems to match, extract, and use.
Start with a clear definition. Then add detail. This works best for:
The definition should establish what something is in a way that can be quoted independently. The expansion then adds context, nuance, or examples.
This pattern helps position your content as a reference point for core concepts — especially when AI systems need a clean, authoritative definition.
AI systems are designed to respond to queries. This pattern aligns your content to that structure.
Order your content as:
The answer should resolve the query in one to two sentences, using the same language or phrasing as the question where possible.
Remaining content can add depth through nuance and edge cases that extend beyond the core answer.
Lists work best when they’re introduced by a clear framing sentence that tells the reader — and the retrieval system — what the items represent.
This pattern works especially well for steps, criteria, features, and takeaways.
Well-structured lists are easier for systems to parse and reuse, especially when each item is clearly defined within the context of the list.
Structure content to make differences explicit. This works well for alternatives (“X vs Y”), tradeoffs, and decision-making criteria. You can use:
Content that clearly outlines differences is easier for AI systems to extract and reuse in answers that involve evaluation or recommendations.
Most AI surfacing issues come back to content structure. When structure is weak, answers are harder to identify and extract. That tends to show up in the form of:
Long paragraphs with key points buried inside make it harder to isolate a clear answer. Without strong subheadings to define what each section covers, systems have fewer signals to identify where that answer lives.
Ask:
Headers like “Overview,” “Introduction,” or “Key Takeaways” don’t provide enough signal about what the section actually contains.
Headings help systems understand what a section covers and how it relates to a query. When they’re vague, the relationship between section and query becomes less explicit.
Ask:
When the answer appears halfway through a paragraph, it’s harder to isolate as a clean, reusable unit.
AI systems look for segments that clearly resolve a query. When the answer is embedded within surrounding context, it becomes less distinct and more likely to be overlooked or reassembled.
Ask:
When sections overlap, they compete for the same query and weaken the overall signal. Instead of reinforcing the topic, similar sections can fragment it across multiple passages, making it less clear which one should be selected.
Ask:
Clear separation improves both retrieval and selection.
Most teams don’t need to totally rebuild content from scratch. Updating existing content for today’s landscape just requires a few structural changes.
Turn generic sections into clearly defined units, like:
Ensure each section covers a distinct angle and does not repeat or overlap with others. This helps consolidate signal and makes it easier for systems to select and attribute the right passage.
AI systems are already reshaping how content is surfaced, and that shift will continue as answers become more personalized and draw from multiple sources.
As a result, page-level ranking matters less on its own. Content value is shifting toward contribution — how clearly a piece of content can inform, support, or shape an answer.
The content that performs best will be:
Content that meets these criteria is more likely to be surfaced, reused, and attributed as AI-mediated search continues to evolve.
An Italian TV station has claimed ownership of Nvidia’s DLSS 5 trailer, proving that YouTube’s copyright system is absurdly broken Who owns Nvidia’s DLSS 5 trailer: Nvidia, or a bunch of Italians and their TV station? The Italian broadcaster La7 has blocked Nvidia’s DLSS5 reveal trailer, citing copyright grounds. Why? La7 showcased the trailer during […]
The post Nvidia DLSS 5 Trailer taken down by Italians, yes really appeared first on OC3D.












ChatGPT Search is citing fewer websites per response after GPT-5.3 Instant became the default experience.
The post ChatGPT Search Is Citing Fewer Sites, Data Shows appeared first on Search Engine Journal.

Cliptude helps creators produce documentary-style videos quickly. It researches topics, writes scripts, sources stock footage and relevant A-roll, and assembles a full edit with motion graphics, maps, and timelines. It delivers premium AI voiceovers with natural pacing and exports ready files for YouTube, TikTok, and Instagram. Start from a prompt or script, then download the final cut or separate stems while keeping full rights.

For a long time, links were the primary signal of authority in search. If you wanted visibility, you built backlinks. If you wanted credibility, you earned placements. That still matters — but it’s no longer enough.
In AI-driven search, authority is shaped by how often your brand is mentioned, cited, and clearly associated with a topic. Visibility comes from being referenced in AI-generated answers.
With that shift in mind, the goal is to create content that earns consistent brand mentions and citations — the signals that now drive AEO visibility.
In 2026 organic discovery, authority incorporates entity recognition.
On both Google and LLMs like ChatGPT and AI Overviews, authority is reinforced through:
Since LLMs synthesize information instead of ranking pages, you need repeatable, credible mentions across the web to strengthen your brand’s likelihood of being cited or referenced in AI answers. Importantly, you also need to use your owned media to define your brand entity very clearly.
That makes building authority even more critical. Your content will now be battling with even more competition in the form of AI results in the SERP and AI-produced content from other publishers.
The TL;DR is that you need to establish a clear brand and, underneath that brand, create content that’s so valuable that other experts, journalists, creators, and AI systems repeatedly reference your brand when they’re discussing a topic core to your business.
Dig deeper: How to build an effective content strategy for 2026
You’ll use many of the same SEO principles as a base for AEO-friendly content. Content aligned with Google’s helpful content guidelines — focused on value and user experience — appeals to the people (and LLMs) discussing these concepts and sourcing experts to validate their positions.
That said, to produce truly AEO-friendly content, you need to incorporate formatting that supports LLM extraction.
Key formatting principles include:
If you’re solely focused on AEO, I’d approach your content with these objectives in mind:
To address these objectives, it can be helpful to think beyond blog posts to ideate “reference-grade” assets, including:
Dig deeper: How to create answer-first content that AI models actually cite
Here’s how to turn those principles into a repeatable process for building AEO authority:
Dig deeper: Organizing content for AI search: A 3-level framework
Writing for AEO isn’t at odds with writing for humans. Even from its early days, AEO shared many of the SEO fundamentals derived from appeal to actual users.
That said, there are enough differences with the way LLMs extract and digest content (and the way users ask LLMs for information) that you need to keep specific nuances in mind in your content approach.
With a clearly defined brand on your owned media, and an understanding of the tenets of AEO and how to address them, you should have a good idea how to leverage your team’s expertise for greater visibility on the AI search landscape.










Multical ends double bookings for portfolio careerists, fractionals, multi-hyphenates, and consultants. It syncs your Google, Outlook, and Apple iCloud calendars so every organization sees your real availability across all accounts. It blocks conflicts in real time, lets you set custom rules and filters, and never permanently stores event content.
Use Multical to manage unlimited calendars at one price, create scheduling links for each client or role, and view, create, and edit events in a unified, mobile-friendly calendar. Control what details others can see, revoke access anytime, and keep credentials encrypted.

Since 2021, I’ve worked on more than 350 published guest posts. In that time, I’ve refined a repeatable guest posting outreach process that consistently drives approvals without ever paying for a placement.
Although guest blogging is becoming more difficult, the basics of personalized guest posting outreach remain the same. If your mindset is to create mutual value, this process will work for you in 2026 and beyond.
Your outreach list is a collection of the websites you’ll email to offer guest-written content. You can build your list in several ways.
The easiest way to find potential websites is by googling your niche alongside “write for us.”

Plenty of reputable websites openly accept guest posts and have an established approval process you can find online. That’s the exact approach I used to publish an article on G2’s Learning Hub.
Alternatively, search the name of a prominent person in your niche and add keywords such as “guest post,” “guest author,” or similar. Chances are that if a website has published guest posts from someone in your industry, they’ll be receptive to accepting guest posts from you as well.

Browse your competitors’ backlink profile with an SEO tool. In Semrush, Backlinks is one of the SEO tools under Link Building.

To refine your list, verify which websites have previously published content from guest authors. If, however, all articles on a blog are written in-house and you’re not the Beyoncé of your industry, chances are your guest posting pitch will go unnoticed.

Once you’ve gathered a list of sites that potentially accept guest posts, run them by your website quality criteria.
Consider the website niche, top pages, organic traffic over time, countries where the traffic is coming from, authority score, and outgoing backlinks. You can also automate this step with the API of your favorite SEO tool.
Even the best guest post outreach will fail if you’re writing to the wrong person.
Most people ignore emails that aren’t relevant to them, nor do they forward them to the right colleague.
That’s why you need to do your homework. There’s likely a specific department or person you should be addressing.
Here’s how to find the right person through LinkedIn:

To do this, you can type “content” and browse the results for a content manager, content editor, or similar.
In smaller companies, you can search for “marketing” or “growth” to find who’s the one-person marketing team.
For micro companies, your best contact person might be the founder or co-founder.
Sometimes, you’ll come across companies that have no listed employees on LinkedIn, or their emails are not available. In this case, your only option might be a generic email such as contact@ or support@. For micro companies or in certain niches (typically B2C websites), these emails can still work.
This step helps you protect your sender reputation and ensures your emails end up in the inbox, not the spam folder.
There are two distinct ways to approach guest posting outreach.
Ask whether the website accepts guest-written content. This way, you don’t invest a lot of time upfront into every pitch and your only focus is on building an outreach list.
As the emails aren’t highly personalized (they usually just include the names of the person and the company), they generate a moderate reply rate.
To drive results with this approach, you need a large outreach list so you’ll still get enough opportunities to work with at a 3% to 5% reply rate.
The email you send to company A offers something completely different than the email you’re sending to company B. It takes a lot of time to research and tailor your pitch, but it also enjoys a higher reply rate (around 19%, from my experience).
This approach works best when you have a small outreach list or when you’re pitching to prominent websites.
No matter your outreach approach, you usually need to pitch guest post topics. With basic personalization, you suggest topics only to the websites that reply to you. But with the hyper-personalized email approach, you propose topics in the first email you send.
Top-tier websites typically only accept specific types of guest articles. Find the website’s editorial guidelines by googling “[company name] + guest post” and see their requirements.
Let’s look at HubSpot as an example. They’re only publishing marketing experiments, original data analyses, or super detailed tactical guides.

Similarly, writing a guest article for Zapier’s blog requires specific experience. Generic topics won’t make the cut.

Buffer takes things a step further by opening rounds for guest posting under specific themes.

Following each website’s requirements increases your chances of landing a successful pitch. But most websites are open to a broader range of suggestions.
Some editors have a list of keywords or topics they want to target. They may share it with you so you can choose a topic to write on based on your expertise.
Alternatively, you can bring your own guest post ideas. When that’s the case, you can use a keyword gap analysis to uncover relevant topic ideas.
Let’s say you want to pitch a guest article to monday.com. Here’s how to go about it:

Look only at keywords where competitors are ranking in the top 100 results.
Limit the keyword search volume to 2,000. This filters out broad, highly competitive terms that typically require long-form, comprehensive guides to rank.


For example, “what is time boxing” has 49% keyword difficulty.

After selecting “monday.com,” you see the site has low topical authority for “what is time boxing,” and ranking for it would be very hard.

Looking at “cost management in project management,” the Personal Keyword Difficulty is 60%. While that’s still high, there’s more to consider.

Monday.com’s Authority Score (AS) is 67, while the average in the top 10 is AS 52. Despite this being a competitive keyword, with the right content, monday.com has real ranking potential.

To do this, use the “site:” search operator and add your keyword into Google search.
In this case, “task priority” came up in the keyword gap analysis. While monday.com doesn’t have an article with this keyword in the H1, it does have very similar content on how to create a priority list or prioritize tasks.

Adding extra value is about what else you can bring to the table besides guest content.
Your extra value proposition is unique to your profile, and different value props can appeal to different websites.
For example, I have 11,000 followers on LinkedIn. When reaching out to a project management tool’s blog editor, I can mention that 54% of my followers are founders, executives, or senior-level professionals in small to mid-sized companies — the very people responsible for managing processes and tools within their organizations.
If I’m personalizing this pitch for a lead-generation blog, I can highlight that 35% of my audience works in the marketing or advertising industry.
When it comes to your emails, you need to consider the subject line, the email body, and follow-ups.
In simple terms:
According to BuzzStream’s analysis of six million emails, the best-performing subject lines:
On to the email body: Keep your emails concise and skimmable. Editors rarely have time for long messages.
Finally: follow-ups. Statistically, the more you follow up, the higher your overall campaign reply rate. Some people reply after the first follow-up, others after the third.
My recommendation? Limit follow-ups to two. A third one feels too pushy.
You’ve done a lot of preparation work. It’s finally time to send your emails. Here’s what to consider:
An analysis of 85,000 personalized emails showed the best day to send a cold email is Monday, closely followed by Tuesday and Wednesday. These are the days with the highest email open and reply rates.
The same study suggests you should be sending your emails between 6 to 9 a.m. PT (9 a.m. to 12 p.m. ET). But since most editors are based in different countries, aim to send your email before noon in their local time.
Always give recipients a clear way to opt out of more emails. Without an unsubscribe option, recipients may mark your message as spam. This can damage your sender reputation and reduce future deliverability.
Most outreach tools allow you to track open, reply, and success rates. Let’s break down what each metric tells you.
Track these metrics to identify weak points in your outreach campaigns.
After you establish a baseline, run controlled A/B tests. Send different versions of your campaign to similarly sized groups and compare performance. Change only one variable at a time so you can clearly measure its impact.
Test ideas such as:
Small improvements across different elements of your campaign can compound into measurable gains in success rate.
I mentioned I’ve worked on more than 350 guest articles. But that doesn’t mean they were all published on different websites. When you provide quality, you’re very likely to build lasting relationships that result in ongoing work.
That’s one reason I use keyword gap analysis to choose topics. I target keywords that the website has real potential to rank for. When an article brings meaningful traffic, it becomes much easier to pitch the next one.
To establish lasting relationships with editors:
Below is the guest post outreach template that has delivered the strongest results in my campaigns.
Between 2023 and 2025, I sent more than 300 pitches using variations of this template, primarily to content managers at B2B SaaS companies in the marketing and HR niches. It generated a 19% reply rate, and 18% of sent emails resulted in a published guest post.
Subject: Fresh content ideas for [Company Name]
Hi [First Name],
My name is [Your Name], and I’m the [Your Job Title] at [Your Company], a [short company description].
I’m reaching out to see if [Company Name] is open to guest contributions. I have extensive experience in [your expertise area], having worked on projects for brands such as [Brand 1] and [Brand 2].
Here are a few topic ideas I’d love to propose:
keyword: [primary keyword 1], US search volume: [search volume]
[Proposed Article Title 1]
keyword: [primary keyword 2], US search volume: [search volume]
[Proposed Article Title 2]
keyword: [primary keyword 3], US search volume: [search volume]
[Proposed Article Title 3]
To learn more about my background, you can view my [LinkedIn profile link] or review articles I’ve written for [Publication 1], [Publication 2], and [Publication 3].
If the article is a fit and gets published, I’d be happy to promote it to my community of [audience description or size].
Looking forward to your thoughts,
[Your Name]
Your author profile directly influences your approval rate.
If you’re just starting out and don’t have a portfolio of published work, editors will hesitate to approve your topics. Start by reaching out to small or mid-sized industry blogs.
As you build your portfolio, pitching becomes easier. Publishing on recognized industry websites and creating content that drives measurable results strengthens your credibility and improves your success rate over time.
Bottom line: Invest in your author profile. That’s your biggest asset for successful guest blogging.













Will WordPress's troubled real-time collaboration feature be worth delaying the release of WP 7.0?
The post WordPress’s Troubled Real-Time Collaboration Feature appeared first on Search Engine Journal.






LLM Consensus sends your prompt to GPT-5.2, Claude Opus 4.6, and Gemini 2.5 Pro simultaneously. The models critique each other's responses, then combine the best elements into a single answer with a quality score from 0 to 1. This results in less hallucination and better answers for important questions. There are three modes: fast (~10s), balanced (~25s), and deep (~60s). The standard REST API is OpenAI-compatible. You can pay per request with USDC via the x402 protocol, or use API keys with prepaid credit packs and a usage dashboard.
The Witcher Online’s 2.0 update adds trading, multiplayer boat/horse riding, and more The Witcher 3: The Wild Hunt’s Online mod has received its 2.0 update, transforming the mod into a more MMO-like experience. Now, the mod supports item trading, customisable horses, new emotes, and other feature upgrades. With the addition of horse sync and boat […]
The post The Witcher Online 2.0 has arrived, and it’s nuts appeared first on OC3D.






AvailSim helps travelers find the right eSIM plan worldwide by aggregating offers from trusted providers. It normalizes plan details and calculates true price per GB so you can compare coverage, data, and cost side by side, with independent rankings untouched by affiliate payouts. You also get destination guides, a data calculator, and a device compatibility checker, then purchase directly from the provider.
AI Sign Designer transforms any uploaded image into a production-ready custom sign design with instant pricing. Customers upload a logo, photo, or sketch, the AI converts it to clean vector files, and they get a quote in 2 minutes instead of the usual 48-hour wait. It generates layered SVGs compatible with Illustrator, CorelDRAW, and FlexiSign. It handles neon, channel letters, lightboxes, and more with real-time visual previews. Sign shops embed it on their website to automate quoting from design to production files.



AdaptlyPost is a social media scheduling and management platform that lets you create once and publish to Instagram, TikTok, YouTube, X, and more from a single dashboard. Plan with a visual calendar, queue posts, and track what's going live. Use AI Image Studio and an AI caption co-pilot to generate visuals and copy, then automate posting via API or OpenClaw agents. Collaborate across workspaces and teams, and scale with plans for creators, businesses, and agencies.
PokerBotAI makes desktop poker bots powered by neural networks. PokerX Bot reads the table, decides, and clicks, working in fully automatic or advisory mode. It handles Hold'em, PLO, Short Deck, MTT, and OFC across 20+ rooms. The engine combines 300M real hand histories with 7B simulated scenarios. It also offers club management tools, a managed bot farm with profit sharing, and custom development.
Compare debt payoff strategies and become debt-free faster
Visual trace replay for AI apps to fix bugs in one click
Track the Artemis II mission from your Mac
The AI video model that actually feels alive.
AI Physical Therapy for Athletes
Turn support emails into tickets
Your best QA team — 9x faster, 20х cheaper
AI creative agents for ecommerce brands
Remap Caps Lock to a hyperkey, just hold it + any key
AI SRE that detects, root causes & auto-fixes K8s incidents
Everything in OpenClaw's terminal, you can now do visually
Your AI agent for ad performance
Private Telegram AI agents, live in under a minute
Free local speech-to-text tool
Portable memory for agent workflows







Intel on GitHubIntel will not provide or guarantee development of or support for this project, including but not limited to, maintenance, bug fixes, new releases or updates. Patches to this project are no longer accepted by Intel. If you have an ongoing need to use this project, are interested in independently developing it, or would like to maintain patches for the community, please create your own fork of the project.

Walvee is an AI-powered travel platform where you describe the experience you want and get a full itinerary including flights, hotels, places, and day-by-day planning organized and ready to use. Unlike basic generators, Walvee includes a Concierge that stays with you during the trip: you can ask for restaurants near your hotel, find hidden gems, or add new places to your day on the fly.
You can also explore and "steal" trips from other travelers, customize them, and share your own routes. Walvee is for people who want more than a spreadsheet — they want a companion that adapts before and during the journey.


stackcost is a community-driven database of what it actually costs to run a startup. Founders publicly share their full stacks, monthly bills, and ROI so you can compare tools, spot overkill, and budget with real-world data. Browse verified receipts, leaderboards, and detailed stack pages, then create your profile to contribute your own stack and get discovered.
IslaApp helps small businesses build and launch bilingual websites quickly. Use an AI-powered editor to rewrite text, swap images, and adjust layouts, then publish with one click. Choose from over 75 industry templates in English and Spanish, connect a custom domain, and enjoy SSL, hosting, and built-in analytics. Sell online with an integrated store and ATH Móvil card payments, manage forms and databases, and run AI email campaigns with responsive support.
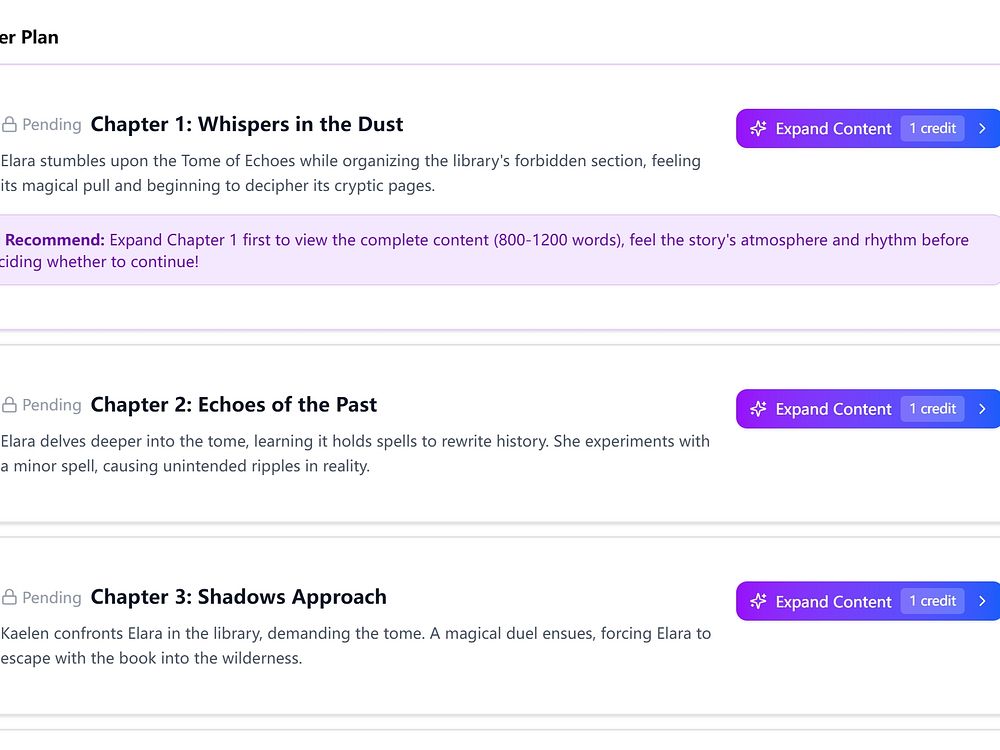
Story Generator helps you create full stories from simple prompts. Choose a genre and get structured narratives with chapters, character arcs, dialogue, and endings in seconds. The tool also builds outlines, plots, prompts, and titles and returns multiple versions per run so you can pick your favorite. Use it to overcome writer’s block, plan scenes, or produce ready-to-read drafts, and export your results. Start free without a credit card, with support for visual storytelling and children’s stories.
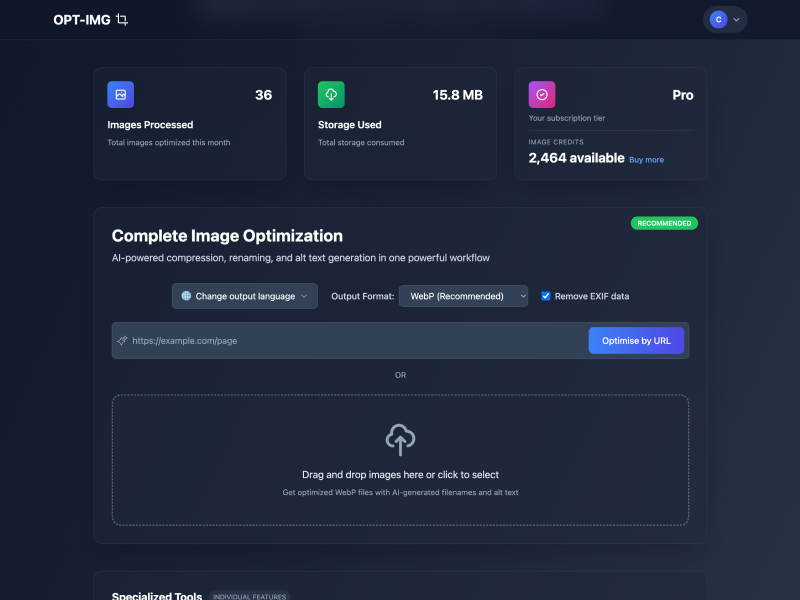
OPT-IMG is an AI-powered image SEO platform that turns raw images into SEO-ready, faster-loading assets. It automatically generates SEO-friendly filenames and alt text and compresses images in a single workflow. Users can batch process images, create responsive outputs, and export optimized assets at scale. OPT-IMG helps improve image search visibility, page speed, and Core Web Vitals for eCommerce sites, blogs, and content teams.

There will be gaps in enforcement until there is a definitive solution to ensure that the same standards apply to all platforms.
The data contracting firm works with all the major AI providers, including Anthropic, OpenAI and Meta, and was hit by hackers last week, per Wired.
The enhanced protections will help musicians who use the app’s SoundOn service identify misused audio tracks and combat copyright violations.
Google, Meta, Microsoft and Snapchat said they would continue to take steps to protect their platforms following the expiration of the EU ePrivacy Directive.

Musk told banks, law firms and other advisors they need to buy subscriptions to AI chatbot Grok before the June initial public offering, per the New York Times.

Co.Actor helps you grow your personal brand on LinkedIn by learning your tone of voice from your posts and every edit. It surfaces daily, relevant post ideas from industry news and your network, then drafts content that sounds like you and lets you schedule directly to LinkedIn.
Use Co.Actor solo or with your team: each member keeps a unique voice, while shared dashboards, notifications, and analytics reveal what resonates and when to post. Track views, engagement, and follower growth, and get data-backed suggestions for what to publish next.

SurveyJS is an open-source JavaScript form builder that lets you create a custom form platform within any web application. Unlike SaaS tools like Typeform or SurveyMonkey, it is not a hosted service and has no usage limits. You can create unlimited forms using a drag-and-drop interface and collect unlimited responses while keeping full ownership of your data. SurveyJS integrates directly into your application, giving you complete control over the UI and branding. Both the form builder and the forms can be fully white-labelled with no external logos or references.
Salow.IO is an AI deal intelligence platform that analyzes B2B sales conversations and returns a deal health score across 9 dimensions, a confusion diagnostic isolating buyer noise, friction, and seller inconsistency, and three ready-to-send closing paths per deal. It detects signals like stakeholder silence or pricing objections and maps them against sales cycles and buyer profiles for 25+ verticals. The platform learns each rep's writing voice from their sent emails via a three-tier Voice DNA engine, so every response sounds like them, not a chatbot. Reps can upload sales playbooks as Strategic Doctrine, enforced across all outputs.
Esseeoh helps creators turn long videos into SEO-optimized YouTube Shorts and auto-posts them with AI-written titles, keyword-rich descriptions, and niche hashtags. It streamlines discovery so your Shorts get recommended to new viewers without manual edits.
If you haven’t uploaded in three days, it finds a top-performing video, generates a fresh Short, and publishes it to keep your channel active and consistent with minimal setup.





VitalStep provides guided fitness programs tailored to age, goals, and health conditions. Choose from 7-day, 21-session templates that build weight control, fat loss, and cardiovascular endurance with low to moderate intensity exercises safe for osteoporosis, diabetes, gout, and hypertension. Follow clear, gentle routines that improve circulation, support blood sugar and metabolism, and promote relaxation, so you can train confidently without aggravating sensitive joints.





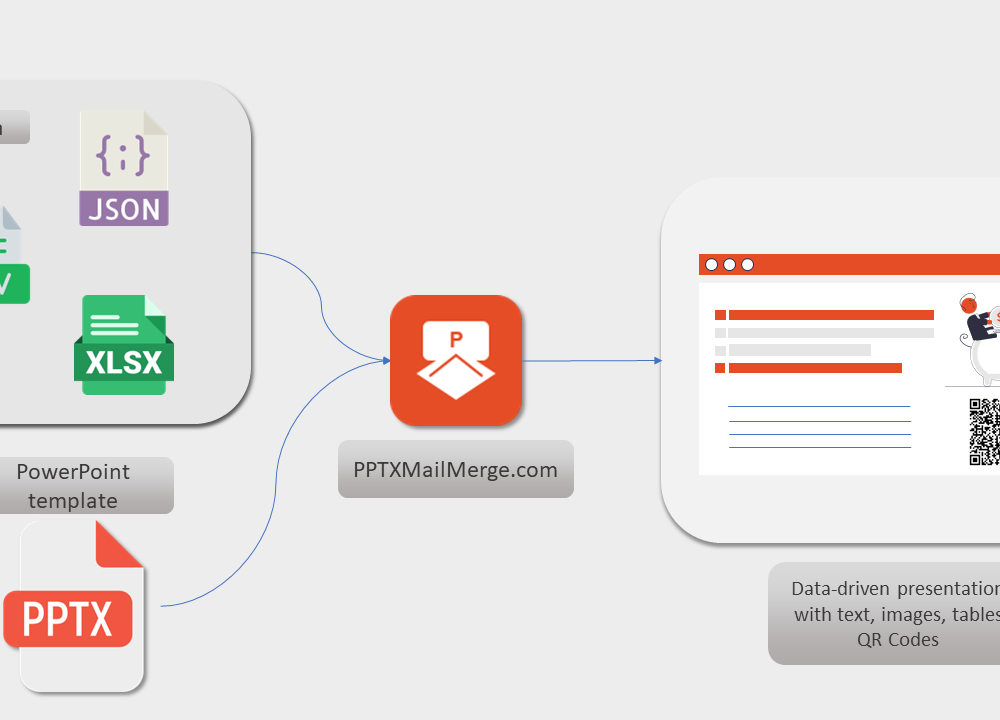
PPTXMailMerge lets you generate data-driven PowerPoint presentations by merging Excel, CSV, or JSON with a PPTX template. Upload a data file and a deck, add smart placeholders, and create personalized slides for each row in seconds. Replace text, images, QR codes, tables, and charts using Excel-like addressing and full JSON traversal, then export a single deck or one file per row. Start free for small jobs or choose short 3-day plans for larger batches with secure processing.










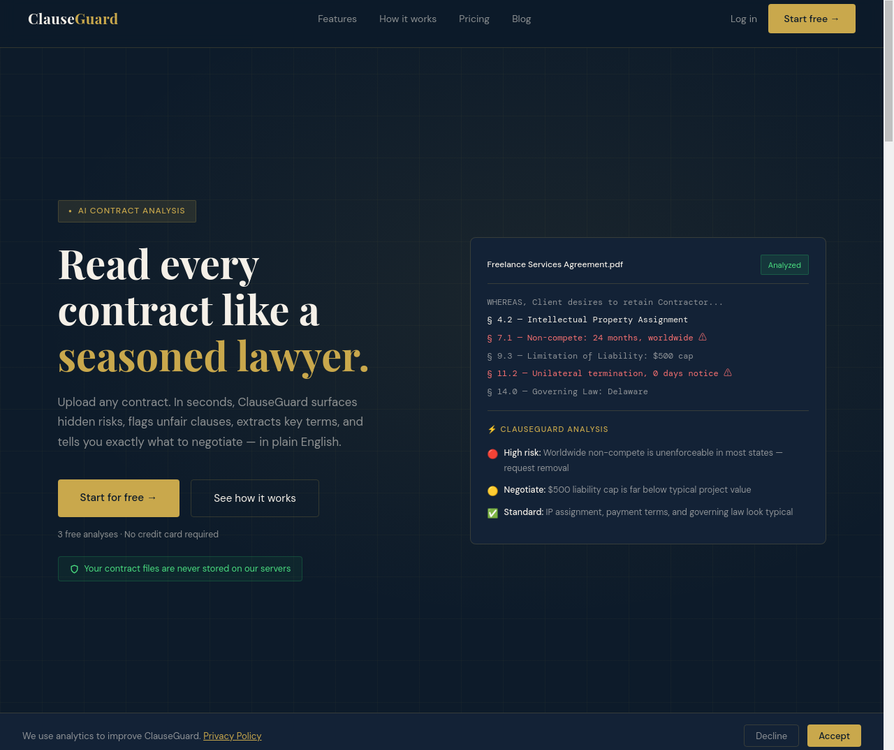
ClauseGuard analyzes contracts to reveal hidden risks, flag unfair clauses, and extract key terms in seconds. Upload a PDF, Word doc, or text file and get a report with a risk score, red flags, plain-English summaries, and ready-to-send counter-language.
It saves your analysis history for deal comparison while keeping files private by not storing uploads. Use it to review NDAs, freelance agreements, and service contracts before signing.
Pelaris is an AI coach that knows your goals, fatigue, RPE, and progress. It builds and continuously evolves science-based, periodized training programs around your life, adapting in real time based on how you train. Not a static plan, but a coaching system that gets smarter every session.
Pelaris supports strength training, running, swimming, cycling, triathlon, CrossFit, and general fitness, using multiple science-based methods per sport. The AI coach remembers your injuries, preferences, and history, adjusting volume, intensity, and exercises as you progress. Built on Flutter, Firebase, and Vertex AI. Privacy-first by design.
ReadThai.Fun is a free Thai script learning tool created by a 20-year Thailand expat. It uses spaced repetition and interleaving to teach all 44 consonants and 32 vowels through 19 tiers ordered by real-world frequency. Each tier requires a 100% gate test before advancing, ensuring genuine mastery. The app includes OCR camera scanning for Thai signs and menus, a 13-language translator, personal dictionary builder, 3-level writing practice, and a text decomposer that breaks Thai words into consonant and vowel components. It works on any device as a PWA and is completely free with full functionality.



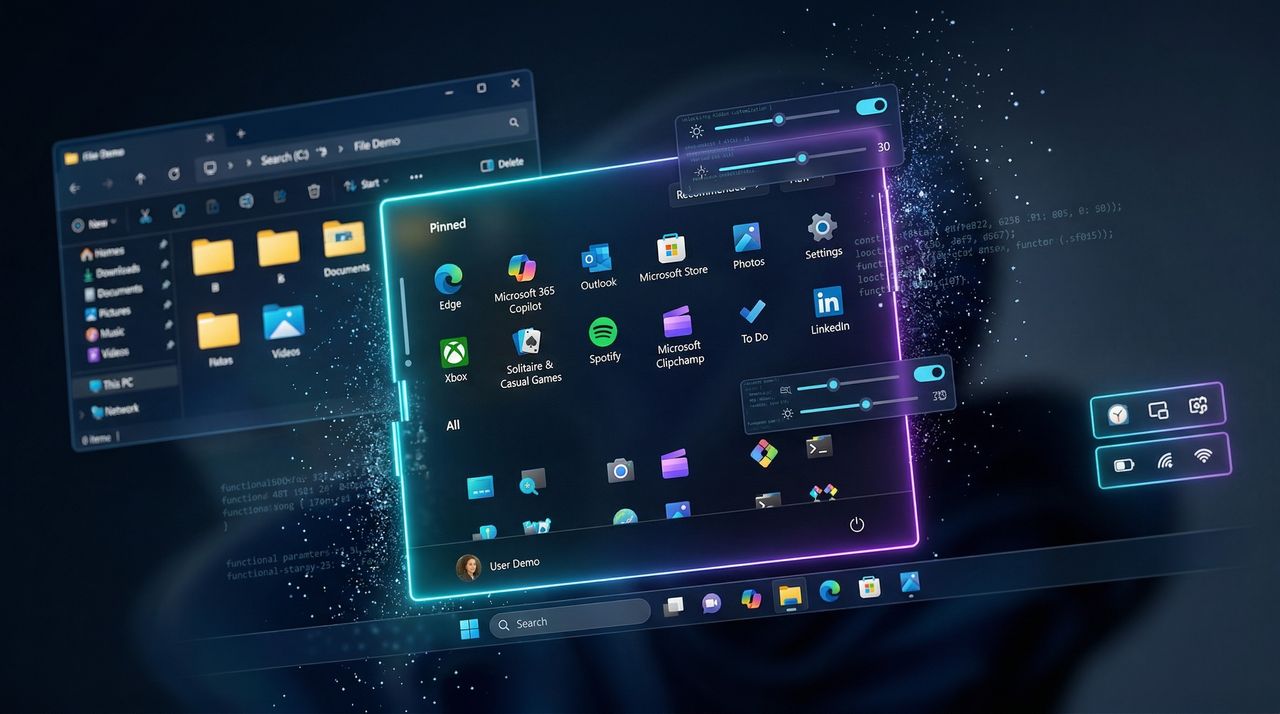





Receivly is an invoicing platform for small businesses and freelancers. Create professional invoices in seconds with auto-numbering and due dates, then see receivables organized as Sent, Overdue, or Paid on a clean dashboard. Automate payment reminders at 7, 14, 21, and 30 days, and keep customer details and default terms in one place for reuse. Mark invoices as paid in one click without bank connections. Your data stays in a secure, isolated workspace so you remain in control.


















How Are You is a 24/7 safety app for families with aging parents. It runs on an Android phone, learns a person’s routine in seven days, and detects anomalies like long stillness, missed wake-up times, or leaving safe zones. When something seems wrong, it emails family with context and GPS coordinates—no app required for them. Data stays on the device, with secure, anonymous summaries used for AI analysis. Setup takes minutes, costs $49 with a 14-day guarantee, then $5/year.




